top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
1.命令格式:
top [参数]
2.命令功能:
显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
3.命令参数:
-d <秒数>:指定 top 命令的刷新时间间隔,单位为秒。-n <次数>:指定 top 命令运行的次数后自动退出。-p <进程ID>:仅显示指定进程ID的信息。-u <用户名>:仅显示指定用户名的进程信息。-H:在进程信息中显示线程详细信息。-i:不显示闲置(idle)或无用的进程。-b:以批处理(batch)模式运行,输出会直接显示在终端,而不会进入交互式的命令行界面。可配合-n x 参数使用。-c:显示完整的命令行而不只是命令名。-s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。-S:累计显示进程的 CPU 使用时间。4.使用实例:
实例1:显示进程信息
命令:
top
输出:
top - 14:06:23 up 70 days, 16:44, 2 users, load average: 1.25, 1.32, 1.35
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9%us, 3.4%sy, 0.0%ni, 90.4%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 32949016k total, 14411180k used, 18537836k free, 169884k buffers
Swap: 32764556k total, 0k used, 32764556k free, 3612636k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 15 0 10368 684 572 S 0.0 0.0 1:30.85 init
说明:
统计信息区:
前五行是当前系统情况整体的统计信息区。下面我们看每一行信息的具体意义。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的系统平均负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于1的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
下面,我们来介绍一下这些 CPU 使用率的意义:来自
us:user time,表示 CPU 执行用户进程的时间,包括 nice 时间。通常都是希望用户空间CPU越高越好。sy:system time,表示 CPU 在内核运行的时间,包括 IRQ 和 softirq。系统 CPU 占用越高,表明系统某部分存在瓶颈。通常这个值越低越好。ni:nice time,具有优先级的用户进程执行时占用的 CPU 利用率百分比。id:idle time,表示系统处于空闲期,等待进程运行。wa:waiting time,表示 CPU 在等待 IO 操作完成所花费的时间。系统不应该花费大量的时间来等待 IO 操作,否则就说明 IO 存在瓶颈。hi:hard IRQ time,表示系统处理硬中断所花费的时间。si:soft IRQ time,表示系统处理软中断所花费的时间。st:steal time,被强制等待(involuntary wait)虚拟 CPU 的时间,此时 Hypervisor 在为另一个虚拟处理器服务。要获取各个 CPU 的使用情况信息,可以通过读取 /proc/stat 文件获取,如下:
[root@VM-16-12-centos ~]# cat /proc/stat
cpu 29030170 3568 31002758 3005209959 10582675 0 280933 0 0 0
cpu0 14538246 1660 15544979 1502180879 5767000 0 175983 0 0 0
cpu1 14491923 1907 15457778 1503029080 4815674 0 104950 0 0 0
...
上面的结果显示了 CPU 的使用情况信息,第一行代表所有 CPU 的总和,而第二行开始表示每个 CPU 核心的使用情况信息。
下面说说这些数据的意义,从第一个数值开始分别代表:user ,nice,system,idle,iowait, irq,softirq,steal。
所以,top 命令的 CPU 使用率计算公式如下:
CPU总时间 = user + nice + system + idle + wait + irq + softirq + steal
%us = user / CPU总时间
%ni = nice / CPU总时间
%sy = system / CPU总时间
%id = idel / CPU总时间
%wa = wait / CPU总时间
%hi = irq / CPU总时间
%si = softirq / CPU总时间
%st = steal / CPU总时间
嗯,看起来还是挺简单的。
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
备注:
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:18537836k +169884k +3612636k = 22GB左右。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
其他使用技巧:
1.多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况。再按数字键1,就会返回到top基本视图界面。
2.高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
我们发现进程id为2570的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
3.进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,敲击键盘“x”(打开/关闭排序列的加亮效果)
4.通过”shift + >”或”shift + <”可以向右或左改变排序列
按一次”shift + >”的效果图,视图现在已经按照%MEM来排序。
实例2:显示 完整命令
命令:
top -c 或者先输入top进入后按c键
实例3:以批处理模式显示程序信息
命令:
top -b
实例4:以累积模式显示程序信息
命令:
top -S
实例5:设置信息更新次数
命令:
top -n 2
说明:
表示更新两次后终止更新显示
实例6:设置信息更新时间
命令:
top -d 3
输出:
说明:
表示更新周期为3秒
实例7:显示指定的进程信息
命令:
top -p 574
5.top交互命令
在top 命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了s 选项, 其中一些命令可能会被屏蔽。
h 显示帮助画面,给出一些简短的命令总结说明
k 终止一个进程。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序
r 重新安排一个进程的优先级别
S 切换到累计模式
s 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s
f或者F 从当前显示中添加或者删除项目
o或者O 改变显示项目的顺序
l 切换显示平均负载和启动时间信息
m 切换显示内存信息
t 切换显示进程和CPU状态信息
c 切换显示命令名称和完整命令行
M 根据驻留内存大小进行排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
《Understanding Linux CPU Load》这篇文章已经非常通俗的解释了什么是 系统平均负载,这里借用一下此文中的例子。
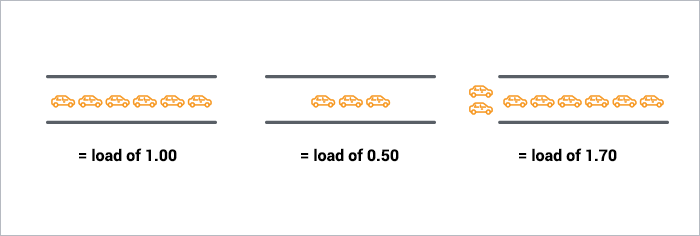
如果将 CPU 比作是桥梁,对于单核的 CPU 就好比是单车道的桥梁。每次桥梁只能让一辆汽车通过,并且要以规定的速度通过。那么:
如果每个时刻都只有一辆汽车通过,那么所有汽车都不用排队,此时桥梁的使用率最高。以平均负载 1.0 表示
如果每隔一段时间才有一辆汽车通过,那么表示桥梁部分时间处于空闲的情况。并且间隔的时间越长,表示桥梁空闲率越高。此时的平均负载小于 1.0
当有大量的汽车通过桥梁时,有些汽车需要等待其他车辆通过后才能继续通行,这时表示桥梁超负荷工作。此时平均负载大于1.0
系统的平均负载与上面的例子一样,在单核 CPU 的环境下:
对于单核 CPU 来说,平均负载 1.0 表示使用率最高。但对于多核 CPU 来说,平均负载要乘以核心数。比如在 4 核 CPU 的系统中,当平均负载为 4.0 时,才表示 CPU 的使用率最高。
在 Linux 系统中,系统负载表示 系统中当前正在运行的进程数量,其包括 可运行状态 的进程数和 不可中断休眠状态 的进程数的和。注意:不可中断休眠状态的进程一般是在等待 I/O 完成的进程。
比如每 5 秒统计一次系统负载,1 分钟内会统计 12 次。然后把每次统计到的系统负载加起来,再除以统计次数,即可得出 系统平均负载。
但这种计算方式有些缺陷,就是预测系统负载的准确性不够高,因为越老的数据越不能反映现在的情况。打个比方,要预测某条公路今天的车流量,使用昨天的数据作为预测依据,会比使用一个月之前的数据作为依据要准确得多。
所以,时间越近的数据,对未来的预测准确性越高。
Linux 内核使用一种名为 指数平滑法 的算法来解决这个问题,指数平滑法的核心思想是对新老数据进行加权,越老的数据权重越低。
指数平滑法:是由 Robert G..Brown 提出的一种加权移动平均法。
其计算公式如下(来源于 Linux 内核代码 kernel/sched/core.c):
load1 = load0 * e + active * (1 - e)
解释一下上面公式的意思:
所以,我们就可以使用上面的公式来预测任何时间的系统平均负载了。比如,我们要预测时间点 n 的系统平均负载,那么可以这样来计算:
load1 = load0 * e + active * (1 - e)
load2 = load1 * e + active * (1 - e)
load3 = load2 * e + active * (1 - e)
...
loadn = loadn-1 * e + active * (1 - e)
现在就只剩下 衰减系数 该如何计算了。
从 Linux 内核的注释可以了解到,计算 1 分钟内系统平均负载的 衰减系数 的计算方式如下:
1 / exp(5sec / 1min)
其中:
也就是说,要计算一分钟的系统平均负载时,需要使用上面的 衰减系数。对于 5 分钟和 15 分钟的 衰减系数 的计算方式分别为:
1 / exp(5sec / 5min)
1 / exp(5sec / 15min)
Linux 内核已经把 1 分钟、5 分钟和 15 分钟的 衰减系数 结果计算出来,并且定义在 include/linux/sched.h 文件中,如下所示:
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
通过上述公式计算出来的 衰减系数 是个浮点数,而在内核中是不能进行浮点数运行的。解决方法是先对 衰减系数 进行扩大,然后在展示时最缩小。所以,上面的 衰减系数 数值是经过扩大 2048 倍后的结果。