
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
Apache ZooKeeper 是一个努力开发和维护、支持高度可靠的分布式协调的开源服务器。
ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。所有这些类型的服务都以某种形式被分布式应用程序使用。每次实施它们时,都需要做大量工作来修复不可避免的错误和竞争条件。由于实施这些类型的服务很困难,应用程序最初通常会忽略它们,这使得它们在发生变化时变得脆弱并且难以管理。即使正确完成,这些服务的不同实现也会导致部署应用程序时的管理复杂性。
zookeeper 集群通常是用来对用户的分布式应用程序提供协调服务的,为了保证数据的一致性,对 zookeeper 集群进行了这样三种角色划分:leader、follower、observer分别对应着总统、议员和观察者。
一个 ZooKeeper 集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 ZooKeeper 集群了。组成 ZooKeeper 集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
重要的一点是,只要集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务。
ZooKeeper 的客户端程序会选择和集群中的任意一台服务器创建一个 TCP 连接,而且一旦客户端和服务器断开连接,客户端就会自动连接到集群中的其他服务器。
一个 ZooKeeper 集群如果要对外提供可用的服务,那么集群中必须要有过半的机器正常工作并且彼此之间能够正常通信。基于这个特性,如果想搭建一个能够允许 N 台机器 down 掉的集群,那么就要部署一个由 2*N+1 台服务器构成的 ZooKeeper 集群。
我们知道,在每台机器数据保持一致的情况下,zookeeper集群可以保证,客户端发起的每次查询操作,集群节点都能返回同样的结果。但是对于客户端发起的修改、删除等能改变数据的操作呢?集群中那么多台机器,你修改你的,我修改我的,最后返回集群中哪台机器的数据呢?
在zookeeper集群中,leader的作用就体现出来了,只有leader节点才有权利发起修改数据的操作,而follower节点即使接收到了客户端发起的修改操作,也要将其转交给leader来处理,leader接收到修改数据的请求后,会向所有follower广播一条消息,让他们执行某项操作,follower 执行完后,便会向 leader 回复执行完毕。当 leader 收到半数以上的 follower 的确认消息,便会判定该操作执行完毕,然后向所有 follower 广播该操作已经生效。
所以zookeeper集群中leader是不可缺少的,但是 leader 节点是怎么产生的呢?其实就是由所有follower 节点选举产生的,而且leader节点只能有一个。
这个时候回到我们的小标题,为什么 zookeeper 节点数是奇数,我们下面来一一来说明:
①、容错率
首先从容错率来说明:(需要保证集群能够有半数进行投票)
2台服务器,至少2台正常运行才行(2的半数为1,半数以上最少为2),正常运行1台服务器都不允许挂掉,但是相对于 单节点服务器,2台服务器还有两个单点故障,所以直接排除了。
3台服务器,至少2台正常运行才行(3的半数为1.5,半数以上最少为2),正常运行可以允许1台服务器挂掉
4台服务器,至少3台正常运行才行(4的半数为2,半数以上最少为3),正常运行可以允许1台服务器挂掉
5台服务器,至少3台正常运行才行(5的半数为2.5,半数以上最少为3),正常运行可以允许2台服务器挂掉
②、防脑裂
脑裂集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的leader节点,导致原有的集群出现多个leader节点的情况,这就是脑裂。
3台服务器,投票选举半数为1.5,一台服务裂开,和另外两台服务器无法通行,这时候2台服务器的集群(2票大于半数1.5票),所以可以选举出leader,而 1 台服务器的集群无法选举。
4台服务器,投票选举半数为2,可以分成 1,3两个集群或者2,2两个集群,对于 1,3集群,3集群可以选举;对于2,2集群,则不能选择,造成没有leader节点。
5台服务器,投票选举半数为2.5,可以分成1,4两个集群,或者2,3两集群,这两个集群分别都只能选举一个集群,满足zookeeper集群搭建数目。
以上分析,我们从容错率以及防止脑裂两方面说明了3台服务器是搭建集群的最少数目,4台发生脑裂时会造成没有leader节点的错误。
ZooKeeper 是分布式应用程序的分布式开源协调服务。它公开了一组简单的原语,分布式应用程序可以在这些原语的基础上构建,以实现用于同步、配置维护以及组和命名的更高级别的服务。它的设计易于编程,并使用仿照熟悉的文件系统目录树结构设计的数据模型。它在 Java 中运行,并绑定了 Java 和 C。
众所周知,协调服务很难做好。它们特别容易出现竞争条件和死锁等错误。ZooKeeper 背后的动机是减轻分布式应用程序从头开始实施协调服务的责任。
ZooKeeper 很简单。ZooKeeper 允许分布式进程通过类似于标准文件系统组织的共享层次命名空间相互协调。名称空间由数据寄存器组成——用 ZooKeeper 的说法称为 znodes——它们类似于文件和目录。与为存储而设计的典型文件系统不同,ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低延迟数。
ZooKeeper 实现非常重视高性能、高可用性、严格有序的访问。ZooKeeper 的性能方面意味着它可以用于大型分布式系统。可靠性方面使其不会成为单点故障。严格的排序意味着可以在客户端实现复杂的同步原语。
ZooKeeper 自我复制。与它协调的分布式进程一样,ZooKeeper 本身旨在通过一组称为集成的主机进行复制。
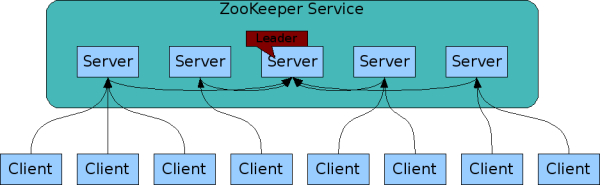
构成 ZooKeeper 服务的服务器必须相互了解。它们在内存中维护状态图像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper 服务就可用。
客户端连接到单个 ZooKeeper 服务器。客户端维护一个 TCP 连接,通过它发送请求、获取响应、获取监视事件和发送心跳。如果与服务器的 TCP 连接中断,客户端将连接到另一台服务器。
ZooKeeper 是有序的。ZooKeeper 用反映所有 ZooKeeper 事务顺序的数字标记每个更新。后续操作可以使用该顺序来实现更高级别的抽象,例如同步原语。
ZooKeeper 很快。它在“读主导”工作负载中特别快。ZooKeeper 应用程序在数千台机器上运行,它在读取比写入更常见的情况下表现最佳,比率约为 10:1。
ZooKeeper 提供的名称空间与标准文件系统的名称空间非常相似。名称是由斜杠 (/) 分隔的一系列路径元素。ZooKeeper 名称空间中的每个节点都由路径标识。
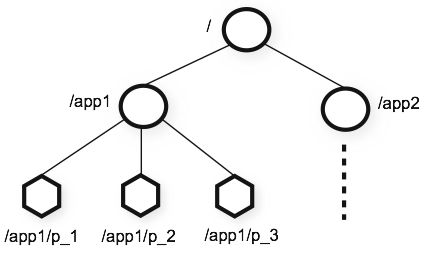
与标准文件系统不同,ZooKeeper 命名空间中的每个节点都可以有与其关联的数据以及子节点。这就像拥有一个允许文件也可以是目录的文件系统。(ZooKeeper 旨在存储协调数据:状态信息、配置、位置信息等,因此每个节点存储的数据通常很小,在字节到千字节范围内。)我们使用术语znode来明确我们正在谈论 ZooKeeper 数据节点。
Znodes 维护一个统计结构,其中包括数据更改的版本号、ACL 更改和时间戳,以允许缓存验证和协调更新。每次 znode 的数据更改时,版本号都会增加。例如,每当客户端检索数据时,它也会收到数据的版本。
存储在命名空间中每个 znode 的数据是原子读取和写入的。读取获取与 znode 关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表 (ACL),用于限制谁可以做什么。
ZooKeeper 也有临时节点的概念。只要创建 znode 的会话处于活动状态,这些 znode 就会存在。当会话结束时,znode 将被删除。当您想要实现[tbd]时,临时节点很有用。
ZooKeeper 支持watches的概念。客户端可以在 znode 上设置监视。当 znode 更改时,将触发并删除 watch。触发监视时,客户端会收到一个数据包,说明 znode 已更改。如果客户端和 Zoo Keeper 服务器之一之间的连接断开,客户端将收到本地通知。这些可以用于[tbd]。
ZooKeeper 非常快速且非常简单。但是,由于它的目标是成为构建更复杂服务(例如同步)的基础,因此它提供了一组保证。这些是:
由于zookeeper集群的运行需要Java运行环境,所以需要首先安装 JDK。
tar -zxvf zookeeper-3.*.tar.gz -C /usr/local/
cd /usr/local/
ln -s zookeeper-*/ zookeeper
cd zookeeper/
cp conf/zoo_sample.cfg conf/zoo.cfg
# vi zoo.cfg
# 修改dataDir
dataDir=/data/zookeeper
sed -i 's#^dataDir=.*#dataDir='${dataDir}'#' /usr/local/zookeeper/conf/zoo.cfg
dataDir=$(grep "^dataDir" /usr/local/zookeeper/conf/zoo.cfg | awk -F '=' '{print $2}')
echo ${dataDir}
mkdir -p ${dataDir}
cp conf/zoo_sample.cfg conf/zoo.cfg
# vi zoo.cfg
# 修改dataDir
dataDir=/data/zookeeper
sed -i 's#^dataDir=.*#dataDir='${dataDir}'#' /usr/local/zookeeper/conf/zoo.cfg
# 修改集群配置
cat >> /usr/local/zookeeper/conf/zoo.cfg <<EOF
server.0=192.168.1.200:2888:3888
server.1=192.168.1.201:2888:3888
server.2=192.168.1.202:2888:3888
EOF
①、tickTime:基本事件单元,这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳;最小 的session过期时间为2倍tickTime
②、dataDir:存储内存中数据库快照的位置,除非另有说明,否则指向数据库更新的事务日志。注意:应该谨慎的选择日志存放的位置,使用专用的日志存储设备能够大大提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会很大程度上影像系统性能。
③、clientPort:监听客户端连接的端口。
④、initLimit:允许follower连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
⑤、syncLimit:表示Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
⑥、server.A=B:C:D
A:其中 A 是一个数字,表示这个是服务器的编号;
B:是这个服务器的 ip 地址;
C:Zookeeper集群内机器通讯使用(Leader监听此端口);
D:选举Leader的端口(所有服务器监听此端口)。
dataDir=$(grep "^dataDir" /usr/local/zookeeper/conf/zoo.cfg | awk -F '=' '{print $2}')
echo ${dataDir}
mkdir -p ${dataDir}
# 在不同节点上依次配置 myid
echo 0 > ${dataDir}/myid
echo 1 > ${dataDir}/myid
echo 2 > ${dataDir}/myid
cat ${dataDir}/myid
bin/zkServer.sh start
bin/zkServer.sh status
bin/zkServer.sh stop
bin/zkServer.sh restart
cat > /usr/lib/systemd/system/zookeeper.service <<EOF
[Unit]
Description=Apache Zookeeper server
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=forking
User=root
Group=root
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
# (file size)
LimitFSIZE=infinity
# (cpu time)
LimitCPU=infinity
# (virtual memory size)
LimitAS=infinity
# (locked-in-memory size)
LimitMEMLOCK=infinity
# (open files)
LimitNOFILE=64000
# (processes/threads)
LimitNPROC=64000
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable zookeeper
systemctl restart zookeeper
systemctl status zookeeper -l
ss -anpt | grep 2181
systemctl stop zookeeper
我们分别对集群三台机器执行启动命令。执行完毕后,分别查看集群节点状态:
出现如下即是集群搭建成功:
[root@localhost ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[root@localhost ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@localhost ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
三台机器,slave1 成功的通过了选举称为了leader,而剩下的两台成为了 follower。这时候,如果你将slave1关掉,会发现剩下两台又会有一台变成了 leader节点。
[root@localhost ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: standalone
10、搭建问题
如果没有出现上面的状态,说明搭建过程出了问题,那么解决问题的首先就是查看日志文件:
zookeeper 日志文件目录在:
dataDir 配置的目录下,文件名称为:zookeeper.out。通过查看日志来解决相应的问题。下面是两种常见的问题:
①、防火墙为关闭
查看防火墙状态:
service iptables status
关闭防火墙:
chkconfig iptables off
②、dataDir 配置的目录没有创建
在 zoo.cfg 文件中,会有对 dataDir 的一项配置,需要创建该目录,并且注意要在该目录下创建 myid 文件,里面的配置和 zoo.cfg 的server.x 配置保持一致。
bin/zkCli.sh
bin/zkCli.sh -server host:por
bin/zkCli.sh -server host:port cmd args
# 修改命令
set path data [version]
# 获取节点的数据,其结果是当前节点的值和stat该路径的值放在一起。
get path [watch]
# 获取节点的子节点列表
ls path [watch]
# 获取节点的子节点列表以及stat该路径
ls2 path [watch]
# 创建新的节点
-s表示创建顺序节点
-e表示创建临时节点
acl表示创建的节点路径
data表示创建的节点的数据内容
create [-s] [-e] path data acl
# 删除节点
delete path [version]
# 删除节点命令,此命令与delete命令不同的是delete不可删除有子节点的节点,但是rmr命令可以删除,注意路径为绝对路径。
rmr path
# 删除配额,-n为子节点个数,-b为节点数据长度。
delquota命令
# 查看节点状态
stat path [watch]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
在zookeeper中,每一次对数据节点的写操作(如创建一个节点)被认为是一次事务,对于每一个事务系统都会分配一个唯一的id来标识这个事务
cZxid就表示事务id,表示该节点是在哪个事务中创建的;
ctime:表示节点创建的时间;
mZxid:最后一次更新时的事务id;
mtime:最后一次更新时的时间;
pZxid: 表示该节点的子节点列表最后一次被修改的事务的id(为当前节点添加子节点,从当前节点的子节点中删除一个或多个子节点都会引起节点的子节点的列表的改变,而修改节点的数据内容则不在此列);
cversion = -1,dataVersion = 0,aclVersion = 0在第一篇博客中已经有过介绍,分别表示子节点列表的版本,数据内容的版本,acl版本;
ephemeralOwner:用于临时节点,表示创建该临时节点的事务id,如果当前节点是永久节点,这个值是固定的,为0;
datalength表示当前节点存放的数据的长度;
numChildren表示当前节点拥有的子节点的个数;