SQL执行顺序
一、总结-太长不看浓缩版
SQL的执行顺序从前到后依次是:
- FROM:获取第一张表,称为原表table1,获取第二张表,称为原表table2,将两张表做笛卡尔积,生成第一张中间表Temp1。
- ON:根据筛选条件,在Temp1上筛选符合条件的记录,生成中间表Temp2。
- JOIN:根据连接方式的不同,选择是否在Temp2的基础上添加外部行。左外就把左表在Temp2中筛选掉的表添加回来生成Temp3,右外则是右表。
- WHERE:筛选表中的记录,对中间表temp3的记录进行过滤,生成temp4。
- GROUP BY:根据聚合键对表进行分组,即在temp4的基础上做分组,生成temp5。
- WITH:应用cube或rollup生成超组,在Temp5的基础上添加超组,生成Temp6。
- HAVING:对组进行筛选,生成temp7。
- SELECT:选取字段,对temp7进行字段的选取,生成temp8。
- DISTINCT:对字段进行去重,对temp8进行去重,生成temp9。
- ORDER BY:按照排序键对表进行排序,对temp9中的表进行排序,生成temp10。
- LIMIT(TOP):对表进行分页,对temp10进行分页,生成temp11。
二、实际演示-啰里啰唆小白版
(一)MySQL版本
8.0.29 社区版
(二)表内容展示说明与创建代码
本次演示用到两张表,存放商品信息的“product”表与存放商店信息的“shopproduct”表。表内容与代码的来源均来自于日本作家MICK所著的《SQL基础教程》,此处仅为学习分享使用,如有不妥请联系我删除。
product表的表结构与具体内容如下:
- product表的表结构
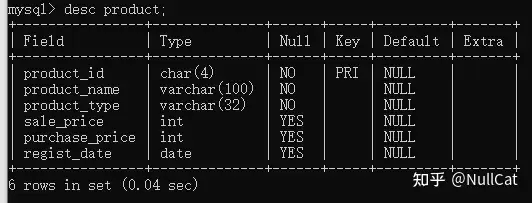
product表-表结构
- product表的字段含义
| 字段名称 | 实际含义 |
|---|---|
| product_id | 商品编号,具有唯一性 |
| product_name | 商品名称 |
| product_type | 商品种类 |
| sale_price | 商品销售单价 |
| purchase_price | 商品进货单价 |
| regist_data | 商品信息登记日期 |
- product表的具体内容
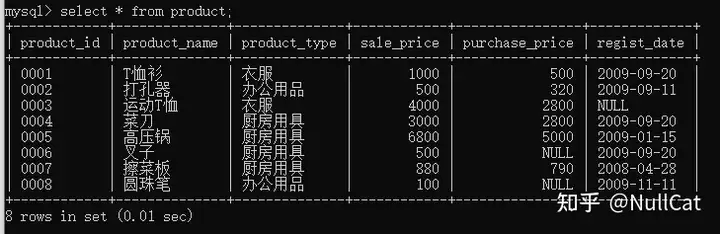
shopproduct表的表结构与具体内容如下:
- shopproduct表的表结构
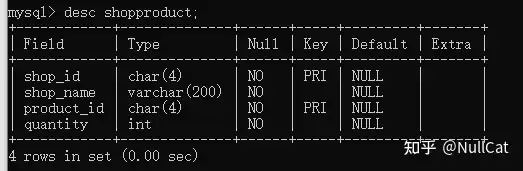
shopproduct表-表结构
- shopproduct表的字段含义
| 字段名称 | 字段含义 |
|---|---|
| shop_id | 商店编号 |
| shop_name | 商店名称 |
| product_id | 商品编号 |
| quantity | 商店内商品库存数量 |
- shopproduct表的具体内容
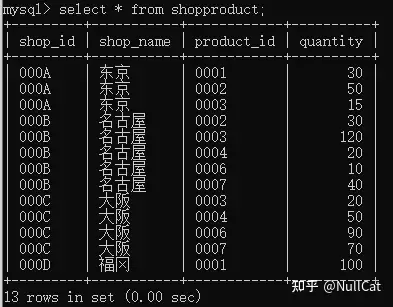
shopproduct表-具体内容
为了方便小伙伴自己动手理解过程,创建表两张表的代码如下:
x#创建product表CREATE TABLE Product(product_id CHAR(4) NOT NULL, product_name VARCHAR(100) NOT NULL, product_type VARCHAR(32) NOT NULL, sale_price INTEGER , purchase_price INTEGER , regist_date DATE , PRIMARY KEY (product_id));
#向product表中插入具体记录INSERT INTO Product VALUES ('0001', 'T恤衫', '衣服', 1000, 500,'2009-09-20');INSERT INTO Product VALUES ('0002', '打孔器', '办公用品', 500,320, '2009-09-11');INSERT INTO Product VALUES ('0003', '运动T恤', '衣服', 4000,2800, NULL);INSERT INTO Product VALUES ('0004', '菜刀', '厨房用具', 3000,2800, '2009-09-20');INSERT INTO Product VALUES ('0005', '高压锅', '厨房用具', 6800,5000, '2009-01-15');INSERT INTO Product VALUES ('0006', '叉子', '厨房用具', 500,NULL, '2009-09-20');INSERT INTO Product VALUES ('0007', '擦菜板', '厨房用具', 880,790, '2008-04-28');INSERT INTO Product VALUES ('0008', '圆珠笔', '办公用品', 100,NULL, '2009-11-11');
#创建shopproduct表CREATE TABLE ShopProduct(shop_id CHAR(4) NOT NULL, shop_name VARCHAR(200) NOT NULL, product_id CHAR(4) NOT NULL, quantity INTEGER NOT NULL, PRIMARY KEY (shop_id, product_id));
#向shopproduct表中插入具体记录INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0001', 30);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0002', 50);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0003', 15);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0002', 30);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0003', 120);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0004', 20);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0006', 10);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0007', 40);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0003', 20);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0004', 50);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0006', 90);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0007', 70);INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000D', '福冈', '0001', 100);(三)推演过程
先放出完整的最终查询代码,后续通过步骤拆解逐步演示MySQL的执行过程。
xxxxxxxxxxselect distinct ifnull(shop_name,'所有店铺') as 店铺名称, avg(sale_price) as 商品销售均价from shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rolluphaving avg(sale_price) < 2000order by 商品销售均价limit 1,1;为了小伙伴们便于理解,我大致说明一下这段代码的业务目的:
- 从商店表(shopproduct表)中选取所有字段,通过左连接的方式从商品表(product表)中获取商店中在售商品的销售单价。
- 计算商店中库存数量小于100的商品销售单价的均值,然后过滤掉商品销售单价均值大于2000的商店,并计算所有店铺销售单价的均值。
- 最终结果按照商品销售额均价升序排序,并且进行分页,每页1条记录,查看第二页的记录。
代码查询结果如下:
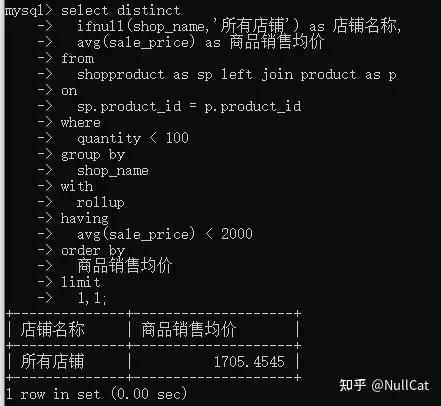
查询最终结果
接下来正式进入演示环节。
- FROM
在MySQL中,首先执行的是FROM子句,FROM子句的完整部分其实包含JOIN,所以在FROM环节就有两张表,不做任何筛选。在最终的总代码中,与FROM相关的代码是:
xxxxxxxxxxfrom shopproduct as sp left join product as p进一步推演过程就是先获取第一张表,shopproducts商店表,如下图:
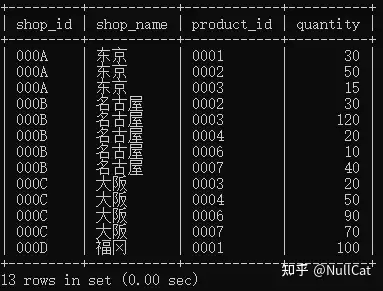
商店表
其次获取第二张表,product商品表,如下图:
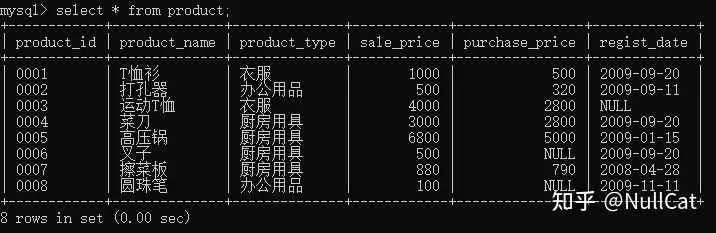
商品表
最后将这两张表做笛卡尔积,得到第一张中间表Temp1,如下图:
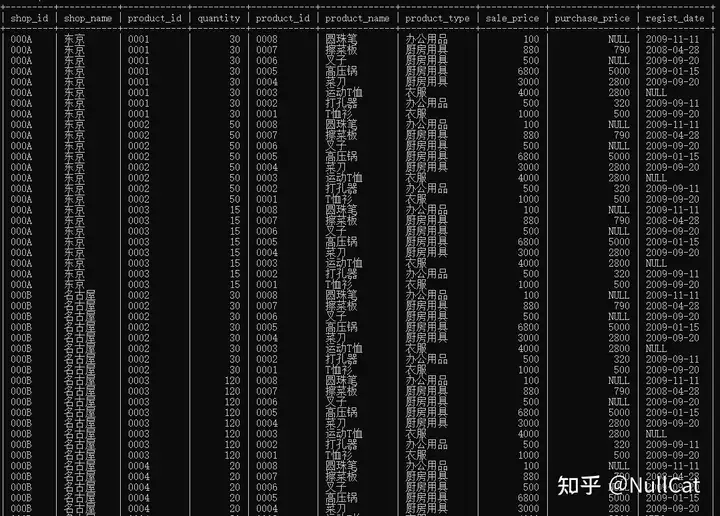
Temp1-两张表的笛卡尔积
在Temp中,虽然预览显示的是字段名,但实际上字段名的完整信息应该是“表名.字段名”,比如shop_id的完整命名应该是“sp.shop_id”,这一点对于两张表中的唯一字段来说意义不大,但是对于像“product_id”这种两张表中都存在的字段来说,表名的前缀是区分两个字段的关键,这是理解后续ON子句筛选条件的关键。
\2. ON
ON子句起到的其实就是一个筛选过滤功能,是在Temp1表的基础上,根据所写的筛选条件进行筛选,筛选出符合条件的中间表。回顾一下我们的查询代码关于ON的部分:
xxxxxxxxxxfrom shopproduct as sp left join product as pon sp.product_id = p.product_id筛选条件是sp表中的product_id字段值等于p表中的product_id表,这个时候SQL做的事情就是对比Temp1表中的sp.product_id字段与p.product_id字段的值,例如第一条记录中sp.product_id的值是"0001",p.product_id的值是"0008",两者不相等,因此这条记录在这个环节就被ON子句过滤掉了,按照记录顺序一条条地执行下去,最终保留符合筛选条件的记录。
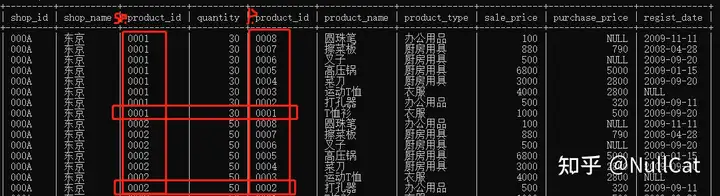
Temp1的对比筛选
所有符合条件的记录会被提小鸡仔一样拎出来,汇合成第二张中间表Temp2,Temp2应该长这样。
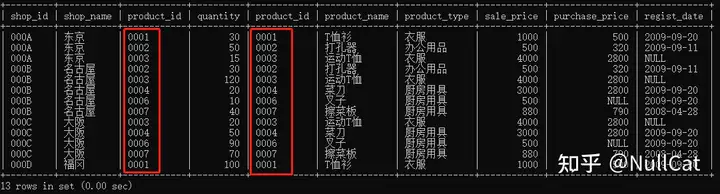
Temp2
仔细观察一下,Temp2中的两个product_id字段中的值都是一一对应的。
\3. JOIN
在这个环节中,根据JOIN方式的不同,会有不同的运行过程。这里主要阐述外连接的运行方式,以我们的代码为例。
xxxxxxxxxxfrom shopproduct as sp left join product as pon sp.product_id = p.product_id选用的是左外连接的方式,因此SQL在这一个环节的执行步骤是这样子的。
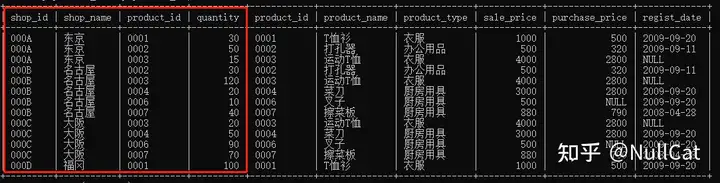
首先遍历左表中的所有行,我们的左表是shopproduct商店表,遍历结果如下:
商店表的遍历结果
然后逐行将所有记录在Temp2表中对比一遍,对比是否已经存在与Temp2表中,红框框出的是Temp2表中的要比较的区域。
Temp2表中的对比区域
如果某条记录不存在,则将该记录添加至Temp2表中生成Temp3, 问题来了,左表只有4个字段,Temp2表有10个字段,其余字段的值如何处理呢?答案是用空值-NULL填充。
在这个案例中,商店表遍历的结果在该Temp2表中是全部存在的,因此不存在添加空行,为了加深理解,我们改用右外连接来理解一下过程,代码如下:
xxxxxxxxxxfrom shopproduct as sp right join product as pon sp.product_id = p.product_id除了将left改为了right之外,其余条件均不变,这个时候的Temp2表还是不变,但此时JOIN遍历的是右表,遍历结果如下:
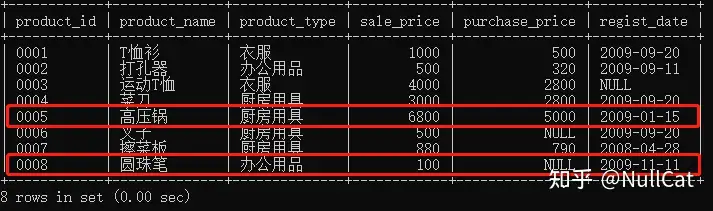
右表遍历结果
红框框出的是在Temp表中不存在的两条记录,此时在Temp2表中对比的区域也相应的发生了变化。
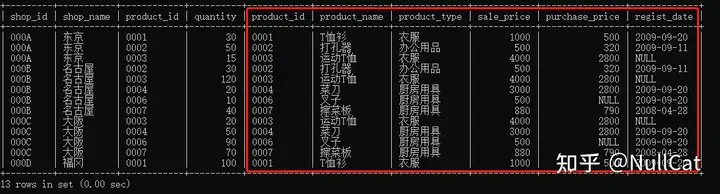
右外时Temp2表中对比的区域
仔细观察遍历结果与Temp2表中的记录可以发现,右表中product_id为'0005'与'0008'的记录在Temp2表中不存在,因为在shopproduct表中不存在product_id为'0005'与'0008'的记录,不满足ON子句中的“sp.product_id = p.product_id”条件,被过滤掉了。
此时JOIN就会把这两条记录添加到Temp2表中,生成新的Temp3表,其余字段用NULL填充,如下图。
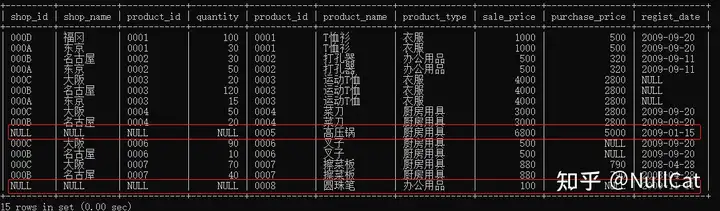
添加了被过滤记录的Temp3表
至此JOIN的执行基本上结束了。但有的小伙伴会问,那三张表呢?那就先对前两张表进行1-3的操作生成Temp3,再将生成的Temp3与第三张表table3进行笛卡尔积,然后重复ON与JOIN的过程,更多的表的执行过程也与此相同。
\4. WHERE
WHERE同样是对表中的记录进行筛选,但是是基于Temp3表所进行的筛选。回顾一下最终代码中WHERE的筛选条件:
xxxxxxxxxxfrom shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100业务层面的含义是筛选出库存小于100的商品记录,可以观察一下Temp3表中的记录,库存大于100的记录有两条:
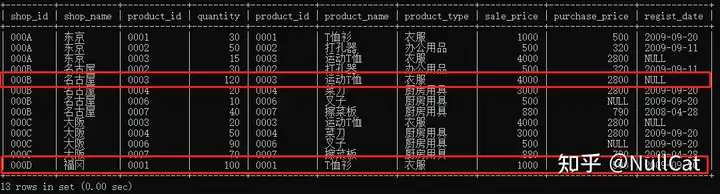
Temp3中库存大于100的记录
这两条记录不符合我们的筛选条件,因此将其去除,去除后的结果作为第四张中间表Temp4,后续GROUP BY子句是在Temp4的基础上进行操作的。这个环节的最终结果Temp4长这样:
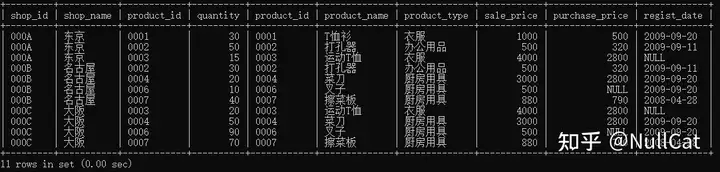
Temp4
需要注意的是,在这个阶段仍然没有对字段数量进行任何删减。
\5. GROUP BY
这个环节的结果我要改用Excel展示了,SQL无法起到展示效果,我们先来看GROUP BY的代码。
xxxxxxxxxxfrom shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_name聚合键所选用的是商店名称字段,正常推演的话这个时候应该有一张Temp5中间表,但这个表长得有点奇怪,用SQL是无法展现出来的。话不多说,直接上图。
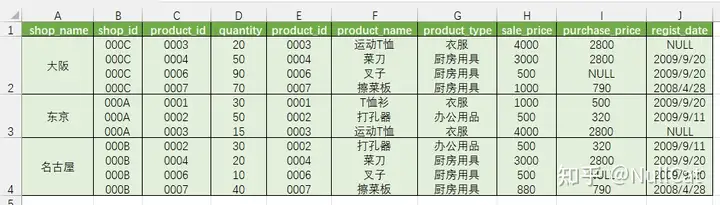
“奇怪”的Temp5
请注意,这个表是不计标题行的话,是只有3条记录的,但是除了shop_name字段之外,其余所有字段中均出现了两个以上的值,而MySQL是关系型数据库,一个单元格(SQL中没有这个说法,但比较形象)中只能有一个值,因此从理论上来说,这张的一张表是不能“存在”于SQL中的。
这个时候就需要引入“组”的概念,group by将shop_name字段分为了三个组。每个组对应的字段中会有多个取值,如果想要它能够被正常使用,那么必须用一种方式将多个取值输入之后输出一个值,这种方式我们叫它聚合函数。由于本篇文章不是专门将group by的,因此这部分就不展开讲了。
\6. WITH
WITH环节的计算方式有两种:CUBE和ROLLUP,由于MySQL支持ROLLUP,因此我们用ROLLUP进行演示。WITH会生成一个或多个超组,CUBE和ROLLUP的区别在于生成超组的方式不同,具体不展开。以我们的代码为例,首先代码如下:
xxxxxxxxxxfrom shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rollup我们是在Temp5的基础上,汇总了一个超级组出来,这个超级组的聚合键是空的,用NULL填充,而其余字段的值则是所有记录的汇总,图会更加直观一些,我们看图。
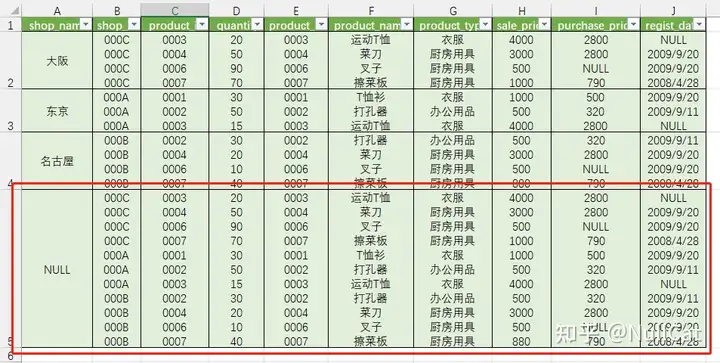
Temp6-红框是超组
在Temp5的基础上添加了一个超组就生成了Temp6,超组的概念请自行百度。
\7. HAVING
由于在HAVING环节还没有进行字段的选取与聚合,因此也就解释了为什么HAVING子句中能使用的元素只有三类:
- 常数
- 聚合函数
- GROUP BY子句中指定的列名(即聚合键)
在这个阶段直接使用未经过聚合处理的字段去做运算时,会有多个值要进行运算。就比如在Temp6表的基础上,去筛选product_id='0003'的组,SQL没法执行啊,SQL对比'0003'与大版组对应的product_id值的时候懵逼了呀,有四个值,我该比较哪个?于是SQL就报错了,表示臣妾做不到啊皇上。
回到我们的最终代码上来,到这个环节,最终代码要关注的部分如下:
xxxxxxxxxxfrom shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rolluphaving avg(sale_price) < 2000从SQL角度来看,HAVING子句会按照组分别计算四个组sale_price字段的均值,然后每组对应的值与2000进行比较,保留值小于2000的组的所有信息,四个组对应的值如下。
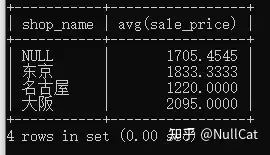
四个组的销售单价均值
其中销售单价均值小于2000的有“东京”组、“名古屋”组以及所有店铺的汇总组,因此最终的Temp7表应该长这样。
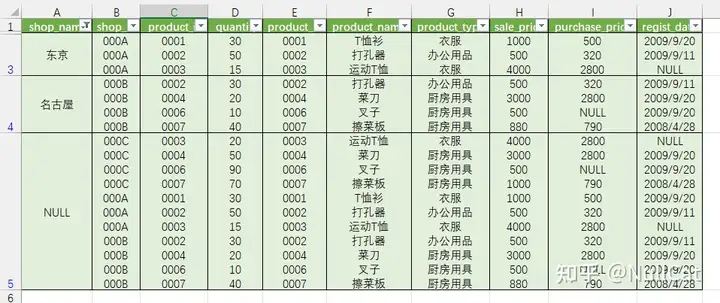
Temp7-不见了“大版”组
需要注意的是,在这个时候,中间表都是以“组”的形式存在的,而非记录的形式。
\8. SELECT
终于到了我们熟悉的字段选取阶段,根据查询代码,我们选取了shop_name与sale_price字段,其中shop_name字段作为聚合键,在每条记录中仅有一个值,因此可以直接选用,而sale_price字段由于存在多个值,必须选用一种聚合方式输出唯一值,在这里我们选用的方式是求均值。
xxxxxxxxxxselect ifnull(shop_name,'所有店铺') as 店铺名称, avg(sale_price) as 商品销售均价from shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rolluphaving avg(sale_price) < 2000因此最终输出的Temp8表如下,仅有两个字段,且是以表记录的形式存在,而非组的形式存在。
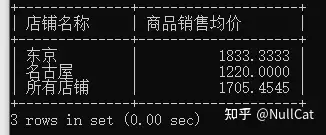
Temp8
\9. DISTINCT
DISTINCT子句起到去重的效果,在Temp8表中不存在重复的记录,因此最终输出的Temp9表与Temp8相同。
Temp9
这一步执行的代码如下:
xxxxxxxxxxselect distinct ifnull(shop_name,'所有店铺') as 店铺名称, avg(sale_price) as 商品销售均价from shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rolluphaving avg(sale_price) < 2000\10. ORDER BY
写到这里,你已经知道接下来会发生什么事情了。ORDER BY起到排序作用,根据代码,排序键是我们的商品销售额均价字段,因此SQL将Temp9按照排序键进行升序排序,生成Temp10。
其实它是生成一个排序的游标而已,不会产生一个新的表。
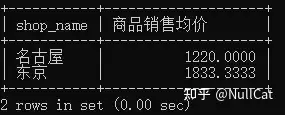
Temp10
执行代码如下:
xxxxxxxxxxselect distinct ifnull(shop_name,'所有店铺') as 店铺名称, avg(sale_price) as 商品销售均价from shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rolluphaving avg(sale_price) < 2000order by 商品销售均价\11. LIMIT(TOP)
最后进行的是分页,我们的查询代码将Temp10的表分成了两页,每页1条记录,第二页的查询生成了Temp11。如下图。
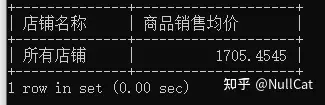
Temp11
到这一步执行的就是我们最开始给出的代码的完整部分。
xxxxxxxxxxselect distinct ifnull(shop_name,'所有店铺') as 店铺名称, avg(sale_price) as 商品销售均价from shopproduct as sp left join product as pon sp.product_id = p.product_idwhere quantity < 100group by shop_namewith rolluphaving avg(sale_price) < 2000order by 商品销售均价limit 1,1;至此,整个执行过程的推演全部结束。
(四)一点拓展
关于FROM所生成的笛卡尔积这一步我查阅了一些资料,但基本都是佐证了这个说法,只是心中不免有些疑惑,难道两张100万行的表做连接时得先生成一张1,000,000,000,000行的临时表吗,这个内存占用也未免太恐怖了。但作为数据分析师的话似乎不需要深入到这个地步,这个疑问只能留待以后进行更深层次的SQL学习时再解答了,感兴趣的小伙伴可以自行了解,有不一样的看法的话欢迎私信我交流。
发布于 2022-06-22 20:06
其他
SQL语言分类
SQL语言分为五大类:
DQL (Data Query Language-数据查询语言) - Select 查询语句不存在提交问题。 DML (Data Manipulation Language-数据操作语言) - Insert、Update、Delete,实现数据的“增删改。” DDL (Data Definition Language-数据定义语言) - Create、Alter、Drop,Truncate ,实现表格的“增删改”。 DTL (Transaction Control Language-事务控制语言) - Commit、Rollback事务提交、回滚语句。 DCL (Data Control Language-数据控制语言) - Grant、Revoke 权限语句。
IF语句
1、IF(expr1 , expr2 , expr3)
如果expr1是true,则if()的返回值为expr2;否则返回值为expr3。
例如:SELECT IF(1 > 2 , 2 , 3); 返回值为3
SELECT IF(1 < 2 , 'YES' , 'NO'); 返回值为NO
如果expr2或expr3中只有一个明确是NULL,则IF()函数的结果类型为非NULL表达式的结果类型
2、IFNULL(expr1 , expr2)
如果expr1不为NULL,则IFNULL()返回值为expr1;否则其返回值为expr2
例如:SELECT IFNULL(1 , 0) ; 返回值为1
SELECT IFNULL(NULL , 10); 返回值为10
nvl函数
- 两个参数的nvl函数:nvl(str1,str2) a. 含义:如果第一个参数不为空的话,则该表达式返回第一个参数的值,若第一个参数为空时,则返回第二个参数的值。 b. 应用场景: i. 可以设置字段如果为空的默认值。例如如果一个人在注册游戏时不填写用户名称时默认取你注册用的微信名称一样。 ii. 也可以用于外关联(join等)时两个表中有重复字段但是值不一样时,可以设置该字段取值的优先级别。例如两个事件表,一个是紧急事件表,另一个是基本事件表,两个表中都有一个字段名为事件紧急程度,这里我们就可以先将两个表进行关联,在设置事件紧急程度时首先取紧急事件表中该字段的内容,如果为空再取基本事件表中该字段的内容。
- 三个参数的nvl函数:nvl2(str1,str2,str3) a. 含义:如果str1的值为空则返回str3,如果不为空则返回str2 b. 应用场景:可以使用与字符串的拼接,如果该字符串为空则直接返回前缀,若字符串不为空,则返回前缀拼接当前字符串之后再返回。
with as
With alias_name as (select1)[,alias_namen as (select n) ]
DISTINCT
distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用 它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的。
distinct必须放在开头,且同时作用于所有字段。
xxxxxxxxxxselect distinct name from tableselect distinct name, id from table
substr
xxxxxxxxxxsubstr(update_time, 1, 10)
MySQL分组查询每组最新的一条数据
https://www.cnblogs.com/java-spring/p/11498457.html
https://blog.csdn.net/weixin_44606481/article/details/133870601
开发中经常会遇到,分组查询最新数据的问题,比如下面这张表(查询每个地址最新的一条记录):
sql如下:
xxxxxxxxxx-- ------------------------------ Table structure for test-- ----------------------------DROP TABLE IF EXISTS `test`;CREATE TABLE `test` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`address` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`create_time` timestamp(0) NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- ------------------------------ Records of test-- ----------------------------INSERT INTO `test` VALUES (1, '张三1', '北京', '2019-09-10 11:22:23');INSERT INTO `test` VALUES (2, '张三2', '北京', '2019-09-10 12:22:23');INSERT INTO `test` VALUES (3, '张三3', '北京', '2019-09-05 12:22:23');INSERT INTO `test` VALUES (4, '张三4', '北京', '2019-09-06 12:22:23');INSERT INTO `test` VALUES (5, '李四1', '上海', '2019-09-06 12:22:23');INSERT INTO `test` VALUES (6, '李四2', '上海', '2019-09-07 12:22:23');INSERT INTO `test` VALUES (7, '李四3', '上海', '2019-09-11 12:22:23');INSERT INTO `test` VALUES (8, '李四4', '上海', '2019-09-12 12:22:23');INSERT INTO `test` VALUES (9, '王二1', '广州', '2019-09-03 12:22:23');INSERT INTO `test` VALUES (10, '王二2', '广州', '2019-09-04 12:22:23');INSERT INTO `test` VALUES (11, '王二3', '广州', '2019-09-05 12:22:23');
平常我们会进行按照时间倒叙排列然后进行分组,获取每个地址的最新记录,sql如下:
xxxxxxxxxxSELECT *FROM (SELECT *FROM testORDER BY create_time DESC) aGROUP BY address;
但是查询结果却不是我们想要的.
原因:在mysql5.7以及之后的版本,如果GROUP BY的子查询中包含ORDER BY,但是 GROUP BY 不与 LIMIT 或 DISTINCT 等特殊查询配合使用,ORDER BY会被忽略掉,所以子查询在 GROUP BY 时排序不会生效,可能是因为子查询大多数是作为一个结果给主查询使用,所以子查询不需要排序,在MySQL内置语句优化器中会将将这条查询语句优化,可以查看执行计划。
xxxxxxxxxxEXPLAINSELECT *FROM (SELECT *FROM testORDER BY create_time DESC) aGROUP BY address;SHOW WARNINGS; # 查看优化后的sql语句,必须和EXPLAIN一起执行
在结果中可以查看被优化后的SQL语句,会变成这样select * from test group by address;,我们可以看到两条语句被合并成了一条,排序没了。
解决思路:如果想要在分组前排序只要打破MySQL语句优化就行,可以通过LIMIT、DISTINCT、MAX() 等操作实现,下面会给出三种实现方法。
第一种:
鉴于以上的原因我们可以添加上 LIMIT 条件来实现功能,子查询使用分页查询后,MySQL语句优化器就不会再去将两条语句合并了,逻辑不同,所以这里子查询排序会生效。
xxxxxxxxxxSELECT *FROM (SELECT *FROM testORDER BY create_time DESC LIMIT 10000) aGROUP BY address
结果为:
对子查询的排序进行limit限制,此时子查询就不光是排序,所以此时排序会生效,但是限制条数却只能尽可能的设置大些
第二种:
使用 DISTINCT 查询进行去重的主要原理是通过先对要进行去重的数据进行分组操作,然后从分组后的每组数据中去一条返回给客户端,MySQL语句优化器会认为子查询中进行的其它处理无法合并,查看执行计划和优化后的语句还是和原语句一致,会先执行子查询然后再执行分组查询。
xxxxxxxxxxSELECT *FROM (SELECT DISTINCT *FROM testORDER BY create_time DESC) AS t1GROUP BY t1.address;
第三种:
通过MAX函数获取最新的时间和地址(因为需要按照地址分组),然后作为一张表和原来的数据进行联查,条件就是地址和时间要和获取的最大时间和地址相等。
xxxxxxxxxx-- 写法1,小表驱动大表SELECT t.*FROM (SELECT address,max(create_time) AS create_timeFROM testGROUP BY address) aLEFT JOIN test t ON t.address = a.address -- 没主键自增id,使用 address + create_time 联合查询AND t.create_time = a.create_time;
使用MAX(id)+分组查询可以查询出每组中最大的id,然后通过每组最大数据id集合关联查出数据即可,因为我这里的业务数据是有序插入的,使用主键自增id和create_time结果是一样的而且使用id查询效率更高。 PS:这里使用内连接查询而不使用 IN 查询是因为我测试时发现连接查询会比 IN 查询性能要高50%以上,这个和底层查询机制有关有兴趣可以查看 IN 查询和连接查询的执行计划。
xxxxxxxxxx-- 写法2,大表驱动小表SELECT t.*FROM test tINNER JOIN (SELECT MAX(id) AS id -- 有主键自增id,使用 id 查询FROM testGROUP BY address) a ON t.id = a.id