Prometheus
![]()
什么是Prometheus?
Prometheus是一个开源系统监控和警报工具包,最初在 SoundCloud构建。自 2012 年成立以来,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发者和用户社区。它现在是一个独立的开源项目,独立于任何公司维护。为了强调这一点,并明确项目的治理结构,Prometheus 于 2016 年加入 云原生计算基金会,成为继Kubernetes之后的第二个托管项目。
Prometheus 将其指标收集并存储为时间序列数据,即指标信息与记录时的时间戳以及称为标签的可选键值对一起存储。
有关 Prometheus 的更详细概述,请参阅 媒体部分链接的资源。
特征
普罗米修斯的主要特点是:
- 具有由度量名称和键/值对标识的时间序列数据的多维数据模型
- PromQL,一种 利用这种维度的灵活查询语言
- 不依赖分布式存储;单个服务器节点是自治的
- 时间序列收集通过 HTTP 上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形模式和仪表板支持
什么是指标?
通俗地说,指标是数字度量。时间序列意味着随时间记录更改。用户想要测量的内容因应用程序而异。对于Web服务器,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。
指标在理解应用程序以某种方式工作的原因方面起着重要作用。假设您正在运行一个 Web 应用程序,发现该应用程序很慢。您将需要一些信息来了解您的应用程序发生了什么。例如,当请求数很高时,应用程序可能会变慢。如果您有请求计数指标,则可以找出原因并增加处理负载的服务器数量。
组件
普罗米修斯生态系统由多个组件组成,其中许多组件是 自选:
- 主要的普罗米修斯服务器,用于抓取和存储时间序列数据
- 用于检测应用程序代码的客户端库
- 支持短期作业的推送网关
- HAProxy、StatsD、Graphite等服务的特殊用途出口商。
- 用于处理警报的警报管理器
- 各种支持工具
大多数普罗米修斯组件都是用Go 编写的,使得 它们易于构建和部署为静态二进制文件。
架构
这张图说明了普罗米修斯的架构及其生态系统组成部分:
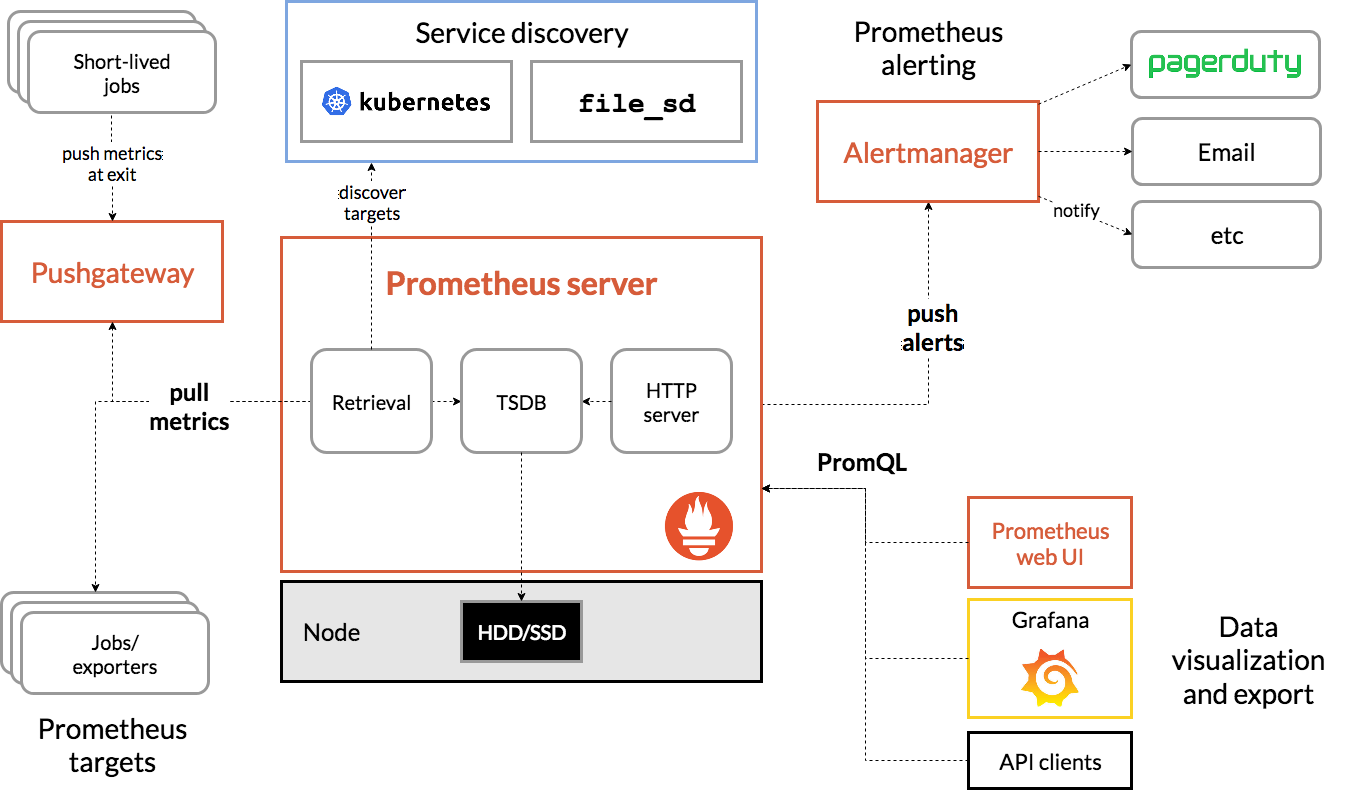
Prometheus 直接从检测的作业中抓取指标,也可以通过 用于短期作业的中间推送网关。它存储所有刮擦的样品 在本地并对此数据运行规则以聚合和记录新时间 从现有数据中序列或生成警报。格拉法纳或 其他 API 使用者可用于可视化收集的数据。
什么时候适合?
普罗米修斯非常适合记录任何纯数字时间序列。它适合 以机器为中心的监控以及高动态监控 面向服务的体系结构。在微服务世界中,它支持 多维度数据收集和查询是特别的强项。
普罗米修斯专为可靠性而设计,成为您访问的系统 在中断期间,以便您快速诊断问题。每个普罗米修斯 服务器是独立的,不依赖于网络存储或其他远程服务。 当基础架构的其他部分损坏时,您可以依赖它,并且 您无需设置广泛的基础架构即可使用它。
什么时候不适合?
普罗米修斯重视可靠性。您可以随时查看统计信息 即使在故障条件下,也可了解您的系统。如果您需要 100% 准确性,例如对于按请求计费,普罗米修斯不是一个好的选择,因为 收集的数据可能不够详细和完整。在这样的一个 在这种情况下,您最好使用其他系统来收集和分析 数据用于计费,普罗米修斯用于其余监控。
其他
基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
服务过程
Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。 Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。 Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。 PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。 Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
三大套件
Server 主要负责数据采集和存储,提供PromQL查询语言的支持。 Alertmanager 警告管理器,用来进行报警。 Push Gateway 支持临时性Job主动推送指标的中间网关。
安装 Prometheus Server
需要安装 golang, 下载、github,可以从packagecloud.io下载RPM包。
wget https://github.com/prometheus/prometheus/releases/download/v2.31.1/prometheus-2.31.1.linux-amd64.tar.gztar -xzf prometheus-2.*.linux-amd64.tar.gz -C /usr/local/cd /usr/local/ln -s /usr/local/prometheus-2.*.linux-amd64/ /usr/local/prometheus
xxxxxxxxxx# 启动cd /usr/local/prometheus/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
创建 Prometheus Systemd 服务
xcat > /etc/systemd/system/prometheus.service << EOF[Unit]Description=Prometheus Time Series Collection and Processing ServerWants=network-online.targetAfter=network-online.target[Service]Type=simpleExecStart=/usr/local/prometheus/prometheus \\--config.file=/usr/local/prometheus/prometheus.yml \\--storage.tsdb.path=/usr/local/prometheus/data \\--storage.tsdb.retention.time=30d \\ # 本地保留数据时长,默认是15d--web.external-url=/ \\ # url路径,如: --web.external-url=/prometheus--web.enable-lifecycle \\ # 启用远程热加载配置文件,调用指令是curl -X POST http://localhost:9090/-/reload--web.console.templates=/usr/local/prometheus/consoles \\--web.console.libraries=/usr/local/prometheus/console_libraries[Install]WantedBy=multi-user.targetEOF
启动 prometheus
xxxxxxxxxxsystemctl daemon-reloadsystemctl enable prometheussystemctl restart prometheussystemctl status prometheussystemctl stop prometheus
web登录
xxxxxxxxxxlocal_ip=$(ip -4 addr | grep inet | grep -v 127.0.0.1 | awk -F '[ /]+' '{print $3}')echo "${local_ip}" | xargs -i echo http://{}:9090
要检查节点的状态,请导航到Status > Targets 要查看抓取的指标,请导航到 http://<server_IP>:9090/metrics
xxxxxxxxxxecho "${local_ip}" | xargs -i echo http://{}:9090/metrics
要检查内存统计信息,例如可用内存,输入 go_memstats_frees_total 并单击执行并在控制台选项卡上查看结果。 结果像一个楼梯的形状
Grafana
![]()
Grafana是用于可视化大型测量数据的开源程序,它提供了强大和优雅的方式去创建、共享、浏览数据。 Dashboard中显示了你不同metric数据源中的数据。 Grafana最常用于因特网基础设施和应用分析,但在其他领域也有用到,比如:工业传感器、家庭自动化、过程控制等等。 Grafana支持热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus等。
安装 Grafana
Ubuntu 和 Debian
xxxxxxxxxxsudo apt-get install -y adduser libfontconfig1wget https://dl.grafana.com/enterprise/release/grafana-enterprise_7.5.11_amd64.debsudo dpkg -i grafana-enterprise_7.5.11_amd64.deb
Red Hat、CentOS、RHEL 和 Fedora
xxxxxxxxxxwget https://dl.grafana.com/enterprise/release/grafana-enterprise-7.5.11-1.x86_64.rpmsudo yum install -y grafana-enterprise-7.5.11-1.x86_64.rpm
独立 Linux 二进制文件
xxxxxxxxxx#wget https://dl.grafana.com/enterprise/release/grafana-enterprise-7.5.11.linux-amd64.tar.gz#tar -zxvf grafana-enterprise-7.5.11.linux-amd64.tar.gz
Grafana 后端在其配置文件中定义了许多配置选项(在 Linux 系统上通常位于/etc/grafana/grafana.ini)。 在此配置文件中,您可以更改默认管理员密码、http 端口、grafana 数据库(sqlite3、mysql、postgres)、身份验证选项(google、github、ldap、auth proxy)以及许多其他选项。
xxxxxxxxxx# The full public facing urlroot_url = %(protocol)s://%(domain)s:%(http_port)s/grafana# Serve Grafana from subpath specified in `root_url` setting. By default it is set to `false` for compatibility reasons.serve_from_sub_path = false
启动grafana
xxxxxxxxxxsystemctl daemon-reloadsystemctl enable grafana-server.servicesystemctl restart grafana-server.servicesystemctl status grafana-server.servicesystemctl stop grafana-server.service
web登录
xxxxxxxxxxlocal_ip=$(ip -4 addr | grep inet | grep -v 127.0.0.1 | awk -F '[ /]+' '{print $3}')echo "${local_ip}" | xargs -i echo http://{}:3000
账号密码默认是 admin
左边齿轮 - Data Sources - Add data source - Prometheus Name: Prometheus URL: http://localhost:9090 Access: Server (default)
点击 Save & Test
切换到Dashboards标签 选择 Prometheus 2.0 Stats -> import
点击 Prometheus 2.0 Stats 可直接跳转到图像页面
重置密码
xxxxxxxxxxgrafana-cli admin reset-admin-password newpassword
AlterManager
Pormetheus的警告由独立的两部分组成。
- Prometheus服务中的警告规则发送警告到Alertmanager。
- 然后这个Alertmanager管理这些警告。包括 沉默silencing, 抑制inhibition, 聚合aggregation,以及通过一些方法发送通知,例如:email,PagerDuty和HipChat。
建立警告和通知的主要步骤:
- 创建和配置Alertmanager
- 启动Prometheus服务时,通过-alertmanager.url标志配置Alermanager地址,以便Prometheus服务能和Alertmanager建立连接。
- 在Prometheus服务中创建警告规则
PrometheusAlert 三种告警状态:Inactive、Pending、Firing
- Inactive 非活动状态,表示正在监控,但是还未有任何警报触发.
- Pending 表示这个警报必须被触发.由于警报可以被分组,压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态.
- Firing 将警报发送到AlertManager,它将按照配置将警报的发送给所有接收者.一旦警报解除,则将状态转到Inactive,如此循环.
安装 AlterManager
创建 AlterManager Systemd 服务
xxxxxxxxxxcat > /etc/systemd/system/alertmanager.service << EOF[Unit]Description=alertmanager[Service]ExecStart=/usr/local/alertmanager/alertmanager \\--config.file=/usr/local/alertmanager/alertmanager.yml--storage.path="data/"--web.external-url=/ # url路径,如: --web.external-url=/alertmanagerExecReload=/bin/kill -HUP $MAINPIDKillMode=processRestart=on-failure[Install]WantedBy=multi-user.targetEOF
启动alertmanager
xxxxxxxxxxsystemctl daemon-reloadsystemctl enable alertmanagersystemctl restart alertmanagersystemctl status alertmanagersystemctl stop alertmanager
node_exporter
node_exporter的作用是用于机器系统数据收集,Prometheus监控服务器CPU、内存、磁盘、I/O等信息,首先需要安装node_exporter。
安装 node_exporter
https://www.jianshu.com/p/7bec152d1a1f https://prometheus.io/docs/guides/node-exporter/ https://github.com/prometheus/node_exporter/releases/ https://github.com/prometheus/node_exporter/releases/download/v1.3.0/node_exporter-1.3.0.linux-amd64.tar.gz
xxxxxxxxxxtar -xzf node_exporter-*.linux-amd64.tar.gz -C /usr/local/cd /usr/local/ln -s /usr/local/node_exporter-*.linux-amd64/ /usr/local/node_exporter
xxxxxxxxxx# 启动cd /usr/local/node_exporter/usr/local/node_exporter/node_exporter &
创建Systemd服务
xxxxxxxxxxcat > /etc/systemd/system/node_exporter.service << EOF[Unit]Description=node_exporterAfter=network.target[Service]Type=simpleExecStart=/usr/local/node_exporter/node_exporterRestart=on-failure[Install]WantedBy=multi-user.targetEOF
启动node_exporter
xxxxxxxxxxsystemctl daemon-reloadsystemctl enable node_exporter.servicesystemctl restart node_exporter.servicesystemctl status node_exporter.servicesystemctl stop node_exporter.service
Node Exporter默认的抓取地址为: http://localhost:9100/metrics
xxxxxxxxxxlocal_ip=$(ip -4 addr | grep inet | grep -v 127.0.0.1 | awk -F '[ /]+' '{print $3}')echo "${local_ip}" | xargs -i echo http://{}:9100/metrics
配置 prometheus 抓取 Node Exporter 的数据
xxxxxxxxxxvim /usr/local/prometheus/prometheus.yml- job_name: 'node'static_configs:- targets: ['localhost:9100']
重启 Prometheus
xxxxxxxxxxsystemctl restart prometheus
访问Prometheus Web,在Status->Targets页面下,我们可以看到我们配置的两个Target,它们的State为UP。 检查Node Exporter,例如CPU,输入 node_cpu_seconds_total 并单击执行并在控制台选项卡上查看结果。
Grafana - 左边加号 - Import - Upload JSON file 添加node-exporter-server-metrics模块 https://grafana.com/grafana/dashboards/405
添加1-node-exporter-0-16-for-prometheus模块(linux监控模块如:CPU MEM 磁盘使用率等) https://grafana.com/grafana/dashboards/8919 此监控模板基于node_exporter 可以更好的展示多项基本监控项
kafka_exporter
https://github.com/danielqsj/kafka_exporter/ 下载 https://github.com/danielqsj/kafka_exporter/releases/download/v1.2.0/kafka_exporter-1.2.0.linux-amd64.tar.gz
安装 kafka_exporter
xxxxxxxxxxtar -zxvf kafka_exporter-1.*.linux-amd64.tar.gz -C /usr/local/cd /usr/local/ln -s /usr/local/kafka_exporter-1.*.linux-amd64/ /usr/local/kafka_exportercd /usr/local/kafka_exporter# kafka_exporter --kafka.server=kafka:9092 [--kafka.server=another-server ...]./kafka_exporter --kafka.server=10.62.248.33:9092 &
docker 方式安装 kafka-exporter
xxxxxxxxxxdocker pull danielqsj/kafka-exporter:v1.4.2docker run -ti --rm -p 9308:9308 danielqsj/kafka-exporter --kafka.server=kafka:9092 [--kafka.server=another-server ...]
kafka Exporter默认的抓取地址为: http://localhost:9308/metrics
xxxxxxxxxxlocal_ip=$(ip -4 addr | grep inet | grep -v 127.0.0.1 | awk -F '[ /]+' '{print $3}')echo "${local_ip}" | xargs -i echo http://{}:9308/metrics
Grafana - 左边加号 - Import - Upload JSON file
其他
好看的模板
https://github.com/starsliao/Prometheus
安装 饼状图插件
直接安装
xxxxxxxxxxgrafana-cli plugins install grafana-piechart-panel
下载安装
xxxxxxxxxxwget -nv https://grafana.com/api/plugins/grafana-piechart-panel/versions/latest/download -O /tmp/grafana-piechart-panel.zipunzip -q /tmp/grafana-piechart-panel.zip -d /tmpmv /tmp/grafana-piechart-panel/ /var/lib/grafana/plugins/grafana-piechart-panel
均需重启
xxxxxxxxxxsystemctl restart grafana-server.service
Prometheus针对nodes告警规则配置
xxxxxxxxxxgroups:- name: examplerules:- alert: 实例丢失expr: up{job="node-exporter"} == 0for: 1mlabels:severity: pageannotations:summary: "服务器实例 {{ $labels.instance }} 丢失"description: "{{ $labels.instance }} 上的任务 {{ $labels.job }} 已经停止了 1 分钟已上了"- alert: 磁盘容量小于 5%expr: 100 - ((node_filesystem_avail_bytes{job="node-exporter",mountpoint=~".*",fstype=~"ext4|xfs|ext2|ext3"} * 100) / node_filesystem_size_bytes {job="node-exporter",mountpoint=~".*",fstype=~"ext4|xfs|ext2|ext3"}) > 95for: 30sannotations:summary: "服务器实例 {{ $labels.instance }} 磁盘不足 告警通知"description: "{{ $labels.instance }}磁盘 {{ $labels.device }} 资源 已不足 5%, 当前值: {{ $value }}"- alert: "内存容量小于 20%"expr: ((node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes )) * 100 > 80for: 30slabels:severity: warningannotations:summary: "服务器实例 {{ $labels.instance }} 内存不足 告警通知"description: "{{ $labels.instance }}内存资源已不足 20%,当前值: {{ $value }}"- alert: "CPU 平均负载大于 4 个"expr: node_load5 > 4for: 30sannotations:sumary: "服务器实例 {{ $labels.instance }} CPU 负载 告警通知"description: "{{ $labels.instance }}CPU 平均负载(5 分钟) 已超过 4 ,当前值: {{ $value }}"- alert: "磁盘读 I/O 超过 30MB/s"expr: irate(node_disk_read_bytes_total{device="sda"}[1m]) > 30000000for: 30sannotations:sumary: "服务器实例 {{ $labels.instance }} I/O 读负载 告警通知"description: "{{ $labels.instance }}I/O 每分钟读已超过 30MB/s,当前值: {{ $value }}"- alert: "磁盘写 I/O 超过 30MB/s"expr: irate(node_disk_written_bytes_total{device="sda"}[1m]) > 30000000for: 30sannotations:sumary: "服务器实例 {{ $labels.instance }} I/O 写负载 告警通知"description: "{{ $labels.instance }}I/O 每分钟写已超过 30MB/s,当前值: {{ $value }}"- alert: "网卡流出速率大于 10MB/s"expr: (irate(node_network_transmit_bytes_total{device!~"lo"}[1m]) / 1000) > 1000000for: 30sannotations:sumary: "服务器实例 {{ $labels.instance }} 网卡流量负载 告警通知"description: "{{ $labels.instance }}网卡 {{ $labels.device }} 流量已经超过 10MB/s, 当前值: {{ $value }}"- alert: "CPU 使用率大于 90%"expr: 100 - ((avg by (instance,job,env)(irate(node_cpu_seconds_total{mode="idle"}[30s]))) *100) > 90for: 30sannotations:sumary: "服务器实例 {{ $labels.instance }} CPU 使用率 告警通知"description: "{{ $labels.instance }}CPU 使用率已超过 90%, 当前值: {{ $value }}"
常用监控面板
405: Node Exporter Server Metrics
3131: Kubernetes All Nodes
3146: Kubernetes Pods
8685: K8s Cluster Summary
10000: Cluster Monitoring for Kubernetes
https://github.com/starsliao/Prometheus