Hadoop
![]()
介绍
Apache™ Hadoop®项目为可靠、可扩展的分布式计算开发开源软件。
Apache Hadoop软件库是一个框架,允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。库本身不是依靠硬件来提供高可用性,而是旨在检测和处理应用程序层的故障,因此在计算机群集之上提供高可用性服务,每个计算机群集都可能容易出现故障。
发展历史
1、Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。 2、2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。 ——分布式文件系统(GFS),可用于处理海量网页的存储(HDFS) ——分布式计算框架(MAPREDUCE),可用于处理海量网页的索引计算问题(MapReduce) ——分布式的结构化数据存储系统(Bigtable),用来处理海量结构化数据(HBase) 3、Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
为什么叫Hadoop Logo为什么是黄色的大象?
 狭义上来说,Hadoop就是单独指代Hadoop这个软件(HDFS+MAPREDUCE)
广义上来说,Hadoop指代大数据的一个生态圈(Hadoop生态圈)
狭义上来说,Hadoop就是单独指代Hadoop这个软件(HDFS+MAPREDUCE)
广义上来说,Hadoop指代大数据的一个生态圈(Hadoop生态圈)
生态系统
该项目包括以下模块:
- Hadoop Common:支持其他Hadoop模块的常用实用程序。
- Hadoop Distributed File System (HDFS™)提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop YARN:用于作业调度和集群资源管理的框架。
- Hadoop MapReduce:一个基于YARN的系统,用于并行处理大型数据集。
Apache的其他Hadoop相关项目包括:
- Ambari™:一个基于Web的工具,用于配置,管理和监控Apache Hadoop集群,包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了用于查看集群运行状况的仪表板,例如热图,以及可视化查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
- Avro™:一个数据序列化系统。
- Cassandra™:一个可扩展的多主数据库,没有单点故障。
- Chukwa™:用于管理大型分布式系统的数据收集系统。
- HBase™:一个可扩展的分布式数据库,支持大型表的结构化数据存储。
- Hive™:提供数据汇总和即席查询的数据仓库基础结构。
- Mahout™:一个可扩展的机器学习和数据挖掘库。
- Ozone™:用于Hadoop的可扩展、冗余和分布式对象存储。
- Pig™:用于并行计算的高级数据流语言和执行框架。
- Spark™:用于Hadoop数据的快速通用计算引擎。Spark 提供了一个简单而富有表现力的编程模型,支持广泛的应用程序,包括 ETL、机器学习、流处理和图形计算。
- Submarine:一个统一的AI平台,允许工程师和数据科学家在分布式集群中运行机器学习和深度学习工作负载。
- Tez™:一个通用的数据流编程框架,基于Hadoop YARN构建,它提供了一个强大而灵活的引擎来执行任意DAG任务,以处理批处理和交互式用例的数据。Tez正在被Hive™,Pig™和Hadoop生态系统中的其他框架以及其他商业软件(例如ETL工具)采用,以取代Hadoop™ MapReduce作为底层执行引擎。
- ZooKeeper™:分布式应用程序的高性能协调服务。

核心组件
Yarn
部署于集群所有节点,计算资源管理和任务调度
ResourceManager模块 统揽全局的核心
- (1)处理客户端请求
- (2)监控NodeManager
- (3)启动或监控ApplicationMaster
- (4)资源的分配与调度
NodeManager模块 管理每个节点上的资源调度
- (1)管理单个节点上的资源
- (2)处理来自ResourceManager的命令
- (3)处理来自ApplicationMaster的命令
AplicationMaster 即为具体的job
- (1)负责数据的切分
- (2)为应用程序申请资源并分配给内部的任务
- (3)任务的监控与容错
Container
- Container 是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU, 磁盘、网络等。

 Yarn基本架构↑
Yarn基本架构↑
 作业提交过程之YARN↑
作业提交过程之YARN↑
 作业提交过程之MapReduce↑
作业提交过程之MapReduce↑

MapReduce
部署于集群所有节点,分布式计算框架,基于磁盘的计算
- Map阶段 - 并行处理输入的数据
- Reduce阶段 - 对Map的结果进行汇总
 MapReduce核心↑
MapReduce核心↑
 MapReduce详细工作流程(一)↑
MapReduce详细工作流程(一)↑
 MapReduce详细工作流程(二)↑
MapReduce详细工作流程(二)↑
 Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle↑
Shuffle机制将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle↑
Shuffle机制将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
HDFS
部署于集群所有节点,分布式文件系统,提供接口
- NameNode 1-2个,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的 DataNode等,有active/standby状态,简称ANN/SNN
- DataNode 每个节点,用于管理节点上的数据: 在本地文件系统存储文件块数据,以及块数据校验和
- SecondaryNameNode 0-1个,用于辅助NameNode管理工作: 用来监控HDFS状态的铺助后台程序,每隔一段时间获取HDFS元数据的快照。
 HDFS组成架构↑
HDFS组成架构↑
 HDFS读数据流程↑
HDFS读数据流程↑
 HDFS写数据流程↑
HDFS写数据流程↑
重要组件
SQL on Hadoop: Hive/impala/presto
Impala
![]() Impala 提高了 Apache Hadoop 上 SQL 查询性能的标准,同时保留了熟悉的用户体验。使用 Impala,您可以实时查询数据,无论是存储在 HDFS 还是 Apache HBase 中,包括 SELECT、JOIN 和聚合函数。此外,Impala 使用与 Apache Hive 相同的元数据、SQL 语法 (Hive SQL)、ODBC 驱动程序和用户界面 (Hue Beeswax),为面向批处理或实时查询提供了一个熟悉且统一的平台。(出于这个原因,Hive 用户可以在很少的设置开销下使用 Impala。
Impala 提高了 Apache Hadoop 上 SQL 查询性能的标准,同时保留了熟悉的用户体验。使用 Impala,您可以实时查询数据,无论是存储在 HDFS 还是 Apache HBase 中,包括 SELECT、JOIN 和聚合函数。此外,Impala 使用与 Apache Hive 相同的元数据、SQL 语法 (Hive SQL)、ODBC 驱动程序和用户界面 (Hue Beeswax),为面向批处理或实时查询提供了一个熟悉且统一的平台。(出于这个原因,Hive 用户可以在很少的设置开销下使用 Impala。
为了避免延迟,Impala 绕过 MapReduce,通过专门的分布式查询引擎直接访问数据,该引擎与商业并行 RDBMS 中的非常相似。结果是性能比 Hive 快几个数量级,具体取决于查询和配置的类型。

与查询 Hadoop 数据的替代方法相比,此方法有许多优点,包括:
- 由于数据节点上的本地处理,避免了网络瓶颈。
- 可以使用单个、开放且统一的元数据存储。
- 不需要昂贵的数据格式转换,因此不会产生开销。
- 所有数据都可以立即查询,ETL 没有延迟。
- 所有硬件都用于Impala查询以及MapReduce。
- 只需一个计算机池即可缩放。
组件
- impalad - Impala 守护进程。计划和执行针对 HDFS、HBase和 Amazon S3 数据的查询。 集群中具有 DataNode 的每个节点上
- statestored - 跟踪集群中所有 impalad实例的位置和状态的名称服务。单节点,大多数生产部署在 namenode 上
- catalogd - 元数据协调服务,将 Impala DDL 和 DML 语句的更改广播到所有受影响的 Impala 节点。单节点,与statestored在同一主机上
- impala-shell -用于向 Impala 守护程序发出查询的命令行界面。
HIVE
![]() 单节点,读取、写入和管理位于分布式存储中的大型数据集、使用 SQL 语法进行查询
单节点,读取、写入和管理位于分布式存储中的大型数据集、使用 SQL 语法进行查询
Metastore模块 使用MYSQL存储结构化的信息,包括: 库名、表名、分区字段、表的类型(是否外部表)、表对应的HDFS数据目录
执行引擎 对sql进行处理[SQL Parser解析器、Physical Plan编译器、Query Optimizer优化器、Execution执行器],封装成MapReduce任务
- 通过Yarn调度执行MapReduce,访问HDFS上的数据,产生执行结果
- 把执行结果加工返回给用户
概念:
- 分区:按照字段分文件夹,伪字段、伪列
- 分桶:分区后最后的字段,比如id值,取哈希/余数分割文件
Hbase
![]() 集群所有节点,让HDFS拥有海量数据下秒级进行增删改查的能力,列数据库存储 参考: 官方文档中文版, 本地版本
集群所有节点,让HDFS拥有海量数据下秒级进行增删改查的能力,列数据库存储 参考: 官方文档中文版, 本地版本
Zookeerper 通过 zk 来做 master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。
- 通过 zk 来保证集群中只有1个 master 在运行,如果 master 异常,会通过竞争机制产生新的 master 提供服务。
- 通过 zk 来监控 RS 的状态,当 RS 有异常的时候,通过回调的形式通知 master RS 上下线的信息。
- 通过 zk 存储元数据的统一入口地址。
HMaster 管理RegionServer
- 分配 Region 到 RegionServer(Region Split后分配新的Region)
- 维护HRegionServer的负载均衡
- 维护集群的元数据信息,如namespace和table的元数据(对表的DDL操作:create,delete,alter)
- 故障转移:RegionServer退出时,分配失效的 Region 到正常的 RegionSener;协调对应 Hlog 的拆分。
HRegionServer 实际处理读写请求
处理 master 为其分配的 Region
处理来自客户端的读写请求
负责和底层 HDFS 的交互,存储数据到 HDFS
负责 Region 变大以后的拆分
负责 Storefile 的合并工作。
预写日志(WAL: write-ahead log),HLog 是HBase的一个WAL实现,每个RS只有一个HLog实例
- 每个RegionServer会将更新(Puts, Deletes) 先记录到预写日志中,然后更新MemStore
- WAL 保存在HDFS 的
/hbase/.logs/里面,每个region一个文件
HRegion 负责存储实际数据,每个RS有多个HRegion 参考: Hbase.html, md
ColumnFamily列族,每个Region的每个列族由多个列组成,相同IO特性的列在一个列族可以提高读取效率
Cell单元格由{RowKey主键, ColumnFamily列族:Column列, Version版本即TimeStamp}唯一确定的单元
Name Space 命名空间(自带hbase和default命名空间) -- Table 表(磁盘目录一对一)
Region 区域(磁盘目录一对一),一个表中的数据按照行[start Rowkey,end Rowkey)区间被横向划分为多个Region
Store 存储(磁盘目录一对一),存储Table的每个Region的每个ColumnFamily单元
MemStore 内存存储,用于保存数据操作,MemStore数据达到阈值时,会Flush到HFile
StoreFile 磁盘文件(磁盘文件),StoreFile 以 HFile 的形式存储于HDFS,每次Flush都会形成一个新的 HFile
- Blocks 块,StoreFiles 由多个Blocks,及其他信息组成
HDFS 为Hbase提供底层数据存储服务

Zookeeper
 集群,至少3个,存储各组件的元信息:配置信息、命名、分布式信息的同步
集群,至少3个,存储各组件的元信息:配置信息、命名、分布式信息的同步
Kudu
![]() 分布式列式数据存储引擎,同时提供低延时的随机读写和高效的数据分析能力,融合HDFS和Hbase的功能
分布式列式数据存储引擎,同时提供低延时的随机读写和高效的数据分析能力,融合HDFS和Hbase的功能
Kudu Master
- 存放table表的Schema信息,负责处理创建表等请求
- 跟踪管理集群中所有的TS,并且在TS异常之后协调数据的重部署
- 存放Tablet到Tablet Server的部署信息
Tablet Server 提供数据的读写服务
- Tablet段
与HBase的区别
Tablet包含2种分区:
- 基于Hash Partition方式:均匀分布,数据排序特点被打乱
- 基于Range Partition方式:按指定的有序Primary Key Columns的组合String顺序进行分区
HBase 仅提供按用户数据RowKey的Range Partition方式
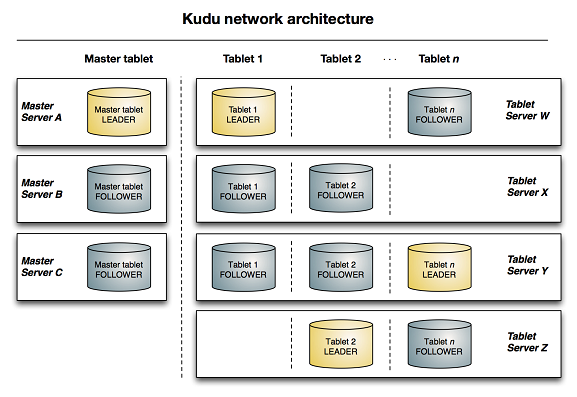
下图显示了一个 Kudu 集群,其中包含三个 master 和多个 tablet 服务器,每个 tablet 服务器服务于多个 tablet。它说明了如何使用 Raft 共识来允许主服务器和平板服务器的领导者和追随者。此外,tablet server 可以是某些 tablets 的领导者,以及其他 tablet 的追随者。领导者以金色显示,而追随者以蓝色显示。
其他组件
Flume
分布式日志采集/聚会/传输系统
- source
- channel
- sunk
Storm
内存计算框架,流式处理,数据从网络导入内存,省去了批处理从HDFS读取数据的过程
Sqoop
数据同步工具,在Hadoop(Hive)与关系型数据库之间进行数据传递
Livy
Apache Livy是一项服务,可以通过REST接口与Spark集群轻松交互。它使 提交 Spark 作业或 Spark 代码片段、同步或异步结果检索以及 Spark 上下文管理,全部通过简单的 REST 接口或 RPC 客户端库进行。Apache Livy还简化了 Spark和应用程序服务器之间的交互,从而允许将Spark用于交互式Web/移动 应用。其他功能包括:
- 具有可由多个客户端用于多个 Spark 作业的长时间运行的 Spark 上下文
- 在多个作业和客户端之间共享缓存的 RDD 或数据帧
- 可以同时管理多个 Spark 上下文,并且 Spark 上下文在群集 (YARN/Mesos) 上运行 Livy 服务器,具有良好的容错性和并发性
- 作业可以作为预编译的jar,代码片段或通过java / scala客户端API提交
- 通过经过身份验证的安全通信确保安全性

Knox
Apache Knox™ Gateway 是一个应用程序网关,用于与 Apache Hadoop 部署的 REST API 和 UI 进行交互。 Knox 网关为与 Apache Hadoop集群的所有 REST 和 HTTP 交互提供单一访问点。
Knox 提供三组面向用户的服务:

- 代理服务 Apache Knox项目的主要目标是通过HTTP资源的代理提供对Apache Hadoop的访问。
- 身份验证服务 身份验证 REST API 访问以及 UI 的 WebSSO 流。LDAP/AD、基于标头的PreAuth、Kerberos、SAML、 OAuth都是可用的选项。
- 客户端 服务客户端开发可以通过 DSL 编写脚本或直接将 Knox Shell 类用作 SDK。KnoxShell 交互式脚本环境 将 groovy shell 的交互式 shell 与 Knox Shell SDK 类相结合,用于与已部署的 Hadoop 集群 中的数据进行交互。
Hadoop常用命令
IMPALA
xxxxxxxxxx# impala-shell 默认端口21050impala-shell [-i impalad_host:port] [-d DEFAULT_DB]impala-shell -i 10.20.0.76:21050 -d cdp_prod
# 显示所有库show databases;show schemas;
# 切换库use [database];
# 显示所有表show tables;
# 删除空数据库drop database test;
# 删除非空数据库drop database test cascade;
# 创建表create table table_name (column1 data_type, column2 data_type);
# 插入数据insert into table_name (column1, column2) values (value1, value2);
# 删除表drop table test;drop table IF EXISTS test;
# 完整备份表create table new_table as select * from old_table;
# 查询结果保存到文件impala-shell -q "select * from test;" -d cdp_prod -B --output_delimiter="\t" --print_header -o test.csv;高级
xxxxxxxxxx# 查看表结构desc [database.table];describe [database.table];# 查看DDL: create tableshow create table [database.table];# 查看分区show partitions [database.table];# 看表的hdfs路径下的文件列表,包括: Path,Size,Partitionshow files in [database.table];# 刷新库的元数据invalidate metadata;# 刷新表table的元数据,在增/删/改变[create/drop/alter]表后使用invalidate metadata [table];# 刷新表table的元数据,在某表加入了新数据,或者有分区的改动[load data、alter table add partition]后使用refresh [table];# 刷新表table的分区partition元数据refresh [table] partition [partition];# 创建函数use cdp_prod;create function year_week location "hdfs://${nameService}/user/udf/udf.jar" SYMBOL="com.convertlab.udf.yearWeek";# 删除函数drop function year_week;# 检查是否已删除invalidate metadata;show functions;
调优
xxxxxxxxxx# 查看sql执行计划explain [sql];# 查看sql语句执行时所消耗的时间和资源,峰值内存(peak memory),预估峰值内存(Est. Peak Mem)summary;# 打印上次执行的 DML 语句或 SELECT 查询的运行时详细报告,仅在查询完成后才可用。profile;# 收集卷信息,表列和分区的数据分布情况,存储在元数据库中,用于优化Impala查询;在进行大表操作时会耗费很时间。compute stats [database.table];
KUDU
xxxxxxxxxx# 确认kudu集群健康状态kudu cluster ksck kudu_master1,kudu_master2,kudu_master3kudu cluster ksck emr-header-1,emr-header-2,emr-header-3
sudo -i kudu cluster ksck emr-header-1,emr-header-2,emr-header-3
# 数据均衡kudu cluster rebalance kudu_master1,kudu_master2,kudu_master3kudu cluster rebalance emr-header-1,emr-header-2,emr-header-3
# 查表kudu table list master(master的主机名)kudu table list emr-header-1,emr-header-2,emr-header-3
# 删表kudu table delete master(master的主机名) 表名kudu table delete emr-header-1,emr-header-2,emr-header-3 impala::data_t1p21.dw_table20220728093334368
# 查看某个 master 节点状态kudu master status emr-header-1
# 查看某个 tserver 节点状态kudu tserver status emr-worker-1HDFS
集群状态
xxxxxxxxxx# 查看nodedata节点状态hdfs haadmin -getAllServiceState#hdfs haadmin -getServiceState nn1#hdfs haadmin -getServiceState nn2# 查看datanode节点状态hdfs dfsadmin -report# 查看 hdfs 集群名hdfs getconf -confKey fs.defaultFScat /etc/hadoop/core-site.xml | grep fs.defaultFS# 获取 NameNode 的主机名hdfs getconf -namenodes
文件操作
xxxxxxxxxx# 查看文件列表hdfs dfs -ls /
# 新建文件夹hdfs dfs -mkdir /test
# 新建文件hdfs dfs -touch /test.txt
# 上传、下载文件、文件夹hdfs dfs -get /spark-tools/hdfs dfs -get /spark-tools/test.txthdfs dfs -put jars /spark-tools/hdfs dfs -put 1.jar /spark-tools/
# 删除文件/文件夹hdfs dfs -rm /test.txt 实际上是移动到trash回收站hdfs dfs -rm -r /test 递归删除hdfs dfs -rm -r -f /test 如果要删除的文件不存在,不显示错误信息hdfs dfs -rm -r -skipTrash /test 跳过回收站,直接删除
# 查看删除后的文件(回收站)hdfs dfs -du -h /user/hadoop/.Trash
# 清理回收站(注:执行完命令后,回收站的数据不会立即被清理,而是先打了一个checkpoint。显示的是一分钟后清除。)hdfs dfs -expunge
# 查看目录文件大小,#第一列为单个文件实际大小,第二列为备份大小hdfs dfs -du -h /
# 复制文件/目录hdfs dfs -cp /path/to/source/file /path/to/destination/directoryhdfs dfs -cp -r /path/to/source/directory /path/to/destination/directory
[root@ip-172-20-105-8 ~]# hdfs dfs -touch /test1touch: Permission denied: user=root, access=WRITE, inode="/":hdfs:hadoop:drwxr-xr-x可知root用户没权限,可以切换到hadoop用户其他
xxxxxxxxxx# 设置数据块平衡器的带宽限制,以避免执行数据块平衡操作时对集群的整体性能产生过大的影响,例如要设置带宽控制为20MB/s,对应值为20971520hdfs dfsadmin -setBalancerBandwidth <bandwidth in bytes per second># 执行负载均衡操作hdfs balancer [-threshold <threshold>] [-policy <policy>] [-idleiterations <idleiterations>]
其中各个参数的含义如下:
-threshold <threshold>:指定数据块的负载均衡阈值,默认为10,表示只有当DataNode的负载超过10%时才会进行数据块迁移。-policy <policy>:指定负载均衡策略,可选的值包括blockpool(默认)和datanode。-idleiterations <idleiterations>:指定在没有进行数据块迁移时的空闲迭代次数,默认为5。
YARN
yarn application
-appStates <States>: 配合-list命令使用,基于应用程序的状态来过滤应用程序。如果应用程序的状态有多个,用逗号分隔。 有效的应用程序状态包含: ALL, NEW, NEW_SAVING, SUBMITTED, ACCEPTED, RUNNING, FINISHED, FAILED, KILLED
-appTypes <Types>: 配合-list命令使用,基于应用程序类型来过滤应用程序。如果应用程序的类型有多个,用逗号分隔。
-list: 返回RUNNING状态的application 任务
-kill <ApplicationId>: kill掉指定的应用程序
-status <ApplicationId>: 打印应用程序的状态。
xxxxxxxxxxyarn application -listyarn application -list -appStates ALLyarn application -status <application ID>yarn application -kill <Application ID>
yarn applicationattempt
一般和yarn container [options] 配合使用
-list <ApplicationId>:获取到应用程序尝试的列表,其返回值 ApplicationAttempt-Id 等于 Application Attempt Id
-status <Application Attempt Id>: 打印应用程序尝试的状态。
yarn applicationattempt -list
AM-Container-Id 指 YARN 应用程序的 Application Master 容器的唯一标识符。在 YARN 中,Application Master(简称 AM)是负责协调和管理整个应用程序执行过程的组件,它负责向 ResourceManager 请求资源,并监控和管理应用程序的执行。
xxxxxxxxxxyarn applicationattempt -list <ApplicationId># 成功的[root@emr-header-1 ~]# yarn applicationattempt -list application_1686800966168_0039Total number of application attempts :1ApplicationAttempt-Id State AM-Container-Id Tracking-URLappattempt_1686800966168_0039_000001 FINISHED container_e09_1686800966168_0039_01_000001 http://emr-header-1.cluster-365468:20888/proxy/application_1686800966168_0039/# 失败重试的[root@CLCSVL1946 cqy]# yarn applicationattempt -list application_1710844797706_83178Total number of application attempts :2ApplicationAttempt-Id State AM-Container-Id Tracking-URLappattempt_1710844797706_83178_000001 FAILED container_e06_1710844797706_83178_01_000001 http://10.37.178.24:8188/applicationhistory/app/application_1710844797706_83178appattempt_1710844797706_83178_000002 FINISHED container_e06_1710844797706_83178_02_000001 http://cdp-ma-prod-node-master3wQVo.mrs-oa04.com:8088/proxy/application_1710844797706_83178/
yarn applicationattempt -status
xxxxxxxxxxyarn applicationattempt -status <Application Attempt Id>[root@emr-header-1 ~]# yarn applicationattempt -status appattempt_1686800966168_0039_000001Application Attempt Report :ApplicationAttempt-Id : appattempt_1686800966168_0039_000001State : FINISHEDAMContainer : container_e09_1686800966168_0039_01_000001Tracking-URL : http://emr-header-1.cluster-365468:20888/proxy/application_1686800966168_0039/RPC Port : 45523AM Host : 10.84.12.210Diagnostics :
yarn container
-list <Application Attempt Id>: 应用程序尝试的Containers列表
-status <ContainerId>: 打印Container的状态
yarn container -list
xxxxxxxxxxyarn container -list <Application Attempt Id>
[root@emr-header-1 ~]# yarn container -list appattempt_1686800966168_0039_000001 Container-Id Start Time Finish Time State Host Node Http Address LOG-URLcontainer_e09_1686800966168_0039_01_000057 Fri Jun 16 11:22:54 +0800 2023 Fri Jun 16 11:22:58 +0800 2023 COMPLETE emr-worker-5.cluster-365468:44479 http://emr-worker-5.cluster-365468:8042 http://emr-header-1.cluster-365468:8188/applicationhistory/logs/emr-worker-5.cluster-365468:44479/container_e09_1686800966168_0039_01_000057/container_e09_1686800966168_0039_01_000057/rootcontainer_e09_1686800966168_0039_01_000056 Fri Jun 16 11:22:54 +0800 2023 Fri Jun 16 11:22:58 +0800 2023 COMPLETE emr-worker-3.cluster-365468:40723 http://emr-worker-3.cluster-365468:8042 http://emr-header-1.cluster-365468:8188/applicationhistory/logs/emr-worker-3.cluster-365468:40723/container_e09_1686800966168_0039_01_000056/container_e09_1686800966168_0039_01_000056/root...略...container_e09_1686800966168_0039_01_000002 Fri Jun 16 11:22:43 +0800 2023 Fri Jun 16 11:28:29 +0800 2023 COMPLETE emr-worker-5.cluster-365468:44479 http://emr-worker-5.cluster-365468:8042 http://emr-header-1.cluster-365468:8188/applicationhistory/logs/emr-worker-5.cluster-365468:44479/container_e09_1686800966168_0039_01_000002/container_e09_1686800966168_0039_01_000002/rootcontainer_e09_1686800966168_0039_01_000001 Fri Jun 16 11:22:38 +0800 2023 Fri Jun 16 11:28:29 +0800 2023 COMPLETE emr-worker-4.cluster-365468:36803 http://emr-worker-4.cluster-365468:8042 http://emr-header-1.cluster-365468:8188/applicationhistory/logs/emr-worker-4.cluster-365468:36803/container_e09_1686800966168_0039_01_000001/container_e09_1686800966168_0039_01_000001/rootyarn container -status
xxxxxxxxxxyarn container -status <ContainerId>[root@emr-header-1 ~]# yarn container -status container_e09_1686800966168_0039_01_000001Container Report :Container-Id : container_e09_1686800966168_0039_01_000001Start-Time : 1686885758838Finish-Time : 1686886109929State : COMPLETEExecution-Type : GUARANTEEDLOG-URL : http://emr-header-1.cluster-365468:8188/applicationhistory/logs/emr-worker-4.cluster-365468:36803/container_e09_1686800966168_0039_01_000001/container_e09_1686800966168_0039_01_000001/rootHost : emr-worker-4.cluster-365468:36803NodeHttpAddress : http://emr-worker-4.cluster-365468:8042Diagnostics :
yarn logs
-applicationId <application ID>: 指定应用程序ID
-appOwner <AppOwner>: 应用的所有者
-containerId <ContainerId>: Container Id
-nodeAddress <NodeAddress>: 节点地址的格式:nodename:port (端口是配置文件中:yarn.nodemanager.webapp.address参数指定)
相关信息:
xxxxxxxxxx# Ali EMR yarn 本地日志路径/mnt/disk[1-4]/log/hadoop-yarn/containers/application_1657965477499_66550# Ali EMR yarn 聚合日志路径/tmp/logs/hadoop/logs-tfile/application_1699120026397_82159/# 聚合日志保留秒数,604800秒(7天) -> 259200秒(3天)yarn.log-aggregation.retain-seconds
日志示例:
xxxxxxxxxxyarn logs -applicationId <application ID> [OPTIONS]
[root@emr-header-1 ~]# yarn logs -applicationId application_1686800966168_0039Container: container_e09_1686800966168_0039_01_000003 on emr-worker-1.cluster-365468_36749LogAggregationType: AGGREGATED==========================================================================================LogType:directory.infoLogLastModifiedTime:Fri Jun 16 11:28:30 +0800 2023LogLength:44053LogContents:ls -l:total 80
...
错误信息搜索: ERROR / exceeded正常结束:
xxxxxxxxxx2024-04-17 14:08:23,871 | INFO | [CoarseGrainedExecutorBackend-stop-executor] | MemoryStore cleared | org.apache.spark.storage.memory.MemoryStore.logInfo(Logging.scala:57)2024-04-17 14:08:23,871 | INFO | [CoarseGrainedExecutorBackend-stop-executor] | BlockManager stopped | org.apache.spark.storage.BlockManager.logInfo(Logging.scala:57)2024-04-17 14:08:23,875 | INFO | [shutdown-hook-0] | Shutdown hook called | org.apache.spark.util.ShutdownHookManager.logInfo(Logging.scala:57)End of LogType:stdout***********************************************************************Container: container_e06_1710844797706_82220_01_000007 on cdp-ma-prod-node-group-1spAM0003.mrs-oa04.com_8041LogAggregationType: AGGREGATED============================================================================================================LogType:stdout.extLogLastModifiedTime:Wed Apr 17 14:08:24 +0800 2024LogLength:0LogContents:End of LogType:stdout.ext***************************************************************************
异常结束:
xxxxxxxxxx2024-04-18 02:08:12,266 | INFO | [shutdown-hook-0] | MemoryStore cleared | org.apache.spark.storage.memory.MemoryStore.logInfo(Logging.scala:57)2024-04-18 02:08:12,266 | INFO | [shutdown-hook-0] | BlockManager stopped | org.apache.spark.storage.BlockManager.logInfo(Logging.scala:57)2024-04-18 02:08:12,269 | INFO | [shutdown-hook-0] | Shutdown hook called | org.apache.spark.util.ShutdownHookManager.logInfo(Logging.scala:57)End of LogType:stdout***********************************************************************Container: container_e06_1710844797706_83178_01_000006 on cdp-ma-prod-node-group-1spAM0003.mrs-oa04.com_8041LogAggregationType: AGGREGATED============================================================================================================LogType:stdout.extLogLastModifiedTime:Thu Apr 18 02:15:02 +0800 2024LogLength:137LogContents:## java.lang.OutOfMemoryError: GC overhead limit exceeded# -XX:OnOutOfMemoryError="kill %p"# Executing /bin/sh -c "kill 1802905"...End of LogType:stdout.ext***************************************************************************
yarn node
-all: 所有的节点,不管是什么状态的。
-list: 列出所有RUNNING状态的节点。支持-states选项过滤指定的状态,节点的状态包含:NEW,RUNNING,UNHEALTHY,DECOMMISSIONED,LOST,REBOOTED。支持--all显示所有的节点。
-states <States>: 和-list配合使用,用逗号分隔节点状态,只显示这些状态的节点信息。
-status <NodeId>: 打印指定节点的状态,NodeId 为上面显示列表中的
xxxxxxxxxxyarn node -list -allyarn node -list -all -showDetails
yarn node -list -states RUNNING
yarn node -status node1:32432yarn queue
-status <QueueName>: 打印队列的状态
xxxxxxxxxxyarn queue -status defaultyarn queue -status <QueueName>yarn rmadmin
-refreshQueues:重载队列的ACL,状态和调度器特定的属性,ResourceManager将重载mapred-queues配置文件
-refreshNodes: 动态刷新dfs.hosts和dfs.hosts.exclude配置,无需重启NameNode。dfs.hosts:列出了允许连入NameNode的datanode清单(IP或者机器名)dfs.hosts.exclude:列出了禁止连入NameNode的datanode清单(IP或者机器名)重新读取hosts和exclude文件,更新允许连到Namenode的或那些需要退出或入编的Datanode的集合。
-refreshUserToGroupsMappings: 刷新用户到组的映射。
-refreshSuperUserGroupsConfiguration: 刷新用户组的配置
-refreshAdminAcls: 刷新ResourceManager的ACL管理
-refreshServiceAclResourceManager: 重载服务级别的授权文件。
-getGroups [username]: 获取指定用户所属的组。
-failover [–forceactive] <serviceId1> <serviceId2>: 启动从serviceId1 到 serviceId2的故障转移。如果使用了-forceactive选项,即使服务没有准备,也会尝试故障转移到目标服务。如果采用了自动故障转移,这个命令不能使用。
-getServiceState <serviceId>: 返回服务的状态。(注:ResourceManager不是HA的时候,时不能运行该命令的)
-getAllServiceState: 返回所有服务的状态。
xxxxxxxxxx# 查看ResourceManager节点状态yarn rmadmin -getAllServiceStateyarn rmadmin -getServiceState rm1yarn rmadmin -getServiceState rm2
sudo -i -u hadoop yarn rmadmin -getAllServiceState
#手动将 rm1 的状态切换到STANDBY,当HA配置中开启了自动故障转移(yarn.resourcemanager.ha.automatic-failover.enabled)时,不可用yarn rmadmin -transitionToStandby rm1
#手动将 rm2 的状态切换到ACTIVEyarn rmadmin -transitionToActive rm2yarn top
查看每个application占用的cpu和内存
命令结果展示
xxxxxxxxxxYARN top - 13:10:32, up 179d, 19:12, 0 active users, queue(s): rootNodeManager(s): 5 total, 5 active, 0 unhealthy, 6 decommissioned, 0 lost, 0 rebooted # NodeManager: 共5个,5个存活,0个不健康,6个已下线Queue(s) Applications: 2 running, 14907 submitted, 0 pending, 14861 completed, 24 killed, 20 failed # job: 2个在运行,14907个已提交,0个等待申请资源,14861个已完成Queue(s) Mem(GB): 211 available, 31 allocated, 0 pending, 0 reserved # 内存:可用211G,已使用31G,共211+31=242GQueue(s) VCores: 155 available, 5 allocated, 0 pending, 0 reserved # CPU:Queue(s) Containers: 5 allocated, 0 pending, 0 reserved # 容器:APPLICATIONID USER TYPE QUEUE PRIOR #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAMEapplication_1657965477499_291044 root spark default 0 4 0 4 0 30G 0G 988417 7521207 10.00 02:20:38 spark-job-gdql-interactive-qapplication_1657965477499_290307 hadoop spark default 0 1 0 1 0 0G 0G 1109367 970696 10.00 12:20:09 Thrift JDBC/ODBC Server
整体资源详情
| 参数 | 说明 |
|---|---|
| available | 剩余可用的资源 |
| allocated | 已经使用的资源 |
| reserved | 已经申请正在分配的资源 |
| pending | 等待申请的资源 |
| available + allocated | Yarn的总资源 |
xxxxxxxxxxAPPID | ApplicationId of the application, e.g. application_1614636765551_1548USER | user e.g. hadoopTYPE | application's Type, e.g. sparkQUEUE | to which the application was submittedPRIORITY | Application's priority, e.g. 0=VERY_HIGH, see JobPriority.java#CONT | the number of used containers#RCONT | the number of reserved containersVCORES | the used Resource - virtual coresRVCORES | the reserved Resource - virtual coresMEM | the used Resource - memory in GBRMEM | the resevered Resource - memroy in GBVCORESECS | the aggregated number of vcores that the application has allocated times the number of seconds the application has been running.MEMSECS | the aggregated amount of memory (in megabytes) the application has allocated times the number of seconds the application has been running.PROGRESS | application's progressTIME | application running time in "dd:HH:mm"NAME | application name
脚本执行yarn top
只要SLEEP_TIME小于yarn top上的默认刷新延迟(默认为3秒),您将在yarn-top.log中获得一个屏幕更新。如果将SLEEP_TIME设置为大于刷新延迟,则将在SLEEP_TIME期间获得尽可能多的更新。
xxxxxxxxxx# 通过管道echo的输出来模拟控制台SLEEP_TIME=2(sleep $SLEEP_TIME; echo -e "q\n\n") | yarn top > yarn-top.log# 过滤yarn-top.log的特殊字符cat yarn-top.log | sed 's/\[K//g' | sed 's/\[7m//g' | sed 's/\[27m//g' | tr -d '\033'
yarn 任务状态
在YARN中,应用程序和Container的状态变化会影响任务的执行和资源分配。下面是YARN中应用程序和Container的状态详细过程:
1)Application 状态
是指YARN应用程序的状态。每个应用程序都有一个唯一的Application ID,并且可以通过ResourceManager API或YARN Web UI来获取应用程序的当前状态。在YARN中,应用程序状态可以有以下状态:
NEW:应用程序刚创建时的状态。应用程序会被分配一个唯一的Application ID,但还没有分配资源,也没有进入资源队列。NEW_SAVING:应用程序等待资源保存。这个状态只存在于开启了Application历史保存的集群上,如果没有保存历史,则该状态的转换不会发生。SUBMITTED:应用程序已经提交给YARN,并在队列中等待调度资源。在该状态下,YARN只是对应用程序进行了初步的运行时配置,但还没有将任何容器分配到该应用程序。ACCEPTED:应用程序已经通过队列,并已经分配了它需要的初始和最小容器。RUNNING:应用程序正在运行中,并具有正在运行的容器。FINISHED:应用程序已经成功完成,并且其最终状态已经保存到YARN应用历史中。FAILED:应用程序运行失败,并且其最终状态已经保存到YARN应用历史中。KILLED:应用程序已被终止,并且其最终状态已经保存到YARN应用历史中。
2)Container 状态
容器状态指的是在YARN集群上运行的应用程序内部的容器状态。在YARN集群上运行的应用程序是通过启动多个容器来实现的,每个容器都运行着应用程序的一部分(如MapReduce中的一个map或reduce任务),并使用一个或多个资源(如内存、CPU等)来执行任务。当一个应用程序启动后,它的容器状态可能有以下几种:
NEW:Container刚刚创建,但还没有分配资源。LOCALIZED:Container已经获取了运行时环境和所需的资源,表示资源已经被分配给某个容器,但资源还未完全在该容器上本地化。在容器执行应用程序之前,需要将应用程序所需的资源(如JAR包、配置文件等)拷贝到容器所在的节点上,并在容器内部完成相关配置。完成本地化操作后,容器就可以开始执行应用程序。RUNNING:Container正在运行,并且已经分配了资源。COMPLETE:Container已经完成工作并退出。EXITED_WITH_SUCCESS:表示容器成功执行完毕,并且已经被清理。EXITED_WITH_FAILURE:表示容器执行失败,并且已经被清理。
从 NEW 状态到 LOCALIZED 状态,Container 会向 NodeManager 发起本地化请求,要求 NodeManager 将所需的资源复制到本地磁盘。从 LOCALIZED 状态到 RUNNING 状态,Container会通过启动进程来运行任务。在运行过程中,Container 可能会由于各种原因失败,进入 FAILED 状态。如果Container 顺利完成任务,则进入 COMPLETE 状态。
综上所述,YARN中应用程序和Container的状态变化对于任务的执行和资源分配非常关键。在使用YARN进行任务调度和管理时,需要对不同状态之间的转换有清晰的理解,以确保任务能够顺利运行和完成。
1)资源不足情况下
在YARN中,当资源不足时,YARN的资源管理器会对应用程序的状态进行调整,以帮助其适应现有的资源情况。下面是YARN中应用程序状态在资源不足的情况下的状态变化:
- 如果应用程序在
SUBMITTED状态时,发现资源不足,那么应用程序会进入ACCEPTED状态。在这种情况下,YARN会尝试为应用程序分配资源,但可能需要等待其他应用程序释放资源后才能成功分配。 - 如果应用程序在
ACCEPTED状态时,发现资源不足,那么应用程序会进入等待状态。在等待状态下,应用程序不会分配任何容器,因为资源不足无法分配。 - 如果应用程序在等待状态中,尝试重新分配资源,但仍然可以找到空闲资源。在这种情况下,应用程序会返回
ACCEPTED状态,并成功分配新的容器。 - 如果应用程序在等待状态中,无法重新分配资源,那么应用程序会转移到
KILLED或FAILED状态。在这种情况下,应用程序无法分配所需的资源,因此无法完成任务。
2)任务超时时间配置
任务等待超时时间:
- 在YARN中,任务等待资源的超时时间可以由任务提交者指定(优先级高),并且也可以在应用程序的配置文件(例如
mapred-site.xml或yarn-site.xml)中进行设置。超时时间指定的是任务等待资源的最长时间,如果在此期间内无法获得所需的资源,则任务将被标记为失败。 - 在默认情况下,任务等待资源的超时时间是YARN调度器指定的一个全局值,可以在
yarn-site.xml配置文件中进行设置。该全局值的默认值是600000毫秒(10分钟)。但也可以针对某个具体任务的特定需求进行调整,方法是在提交任务时构造一个ResourceRequest对象,并指定该对象的超时时间。
在YARN中,可以通过配置文件设置任务等待资源的超时时间,其中包括 mapred-site.xml 和 yarn-site.xml 两个文件。
在 yarn-site.xml 文件中,可以设置以下两个参数来控制任务等待资源的超时时间:
yarn.nodemanager.resource.timeout-ms:这个参数定义了节点管理器等待应用程序可能需要的资源的最长时间。如果等待时间超过此限制,则节点管理器会杀死该应用程序。默认值为10分钟(600000毫秒)。yarn.resourcemanager.resource-tracker.client.thread-count:这个参数定义了资源管理器向节点管理器发送请求的线程数。通过增加这个参数,可以提高资源管理器向节点管理器发送请求的并发性能,从而减少任务等待的时间。
在 mapred-site.xml 文件中,可以设置以下参数来控制 MapReduce 作业等待资源的超时时间:
mapreduce.client.completion.pollinterval:这个参数定义了客户端轮询作业的完成状态的时间间隔。默认值为5000毫秒。mapreduce.client.progressmonitor.pollinterval:这个参数定义了客户端轮询作业的进度状态的时间间隔。默认值为1000毫秒。
History Server API
xxxxxxxxxx/ws/v1/applicationhistory/appshistory_server_host=10.37.178.24port=8188http://${history_server_host}:${port}/ws/v1/applicationhistory/apps
HBASE
基本命令
xbin/hbase shell# 创建一个名为 test 的表,这个表只有一个 列族 为 cfcreate 'test', 'cf'# 查看表listlist 'test'# 查看表结构describe 'test'# 插入些值put 'test', 'row1', 'cf:a', 'value1'put 'test', 'row2', 'cf:b', 'value2'put 'test', 'row3', 'cf:c', 'value3'# 统计行数count 'test'# Scan这个表scan 'test'# Get一行get 'test', 'row1'# Delete一列delete 'test', 'row1', 'cf:a'# Delete一行deleteall 'test', 'row1'# 清空表truncate 'test'# disable 再 drop 这张表,可以清除你刚刚的操作disable 'test'drop 'test'# 关闭shellexit
更新操作
xxxxxxxxxx# 创建命名空间create_namespace 'test'
# 查看所有命名空间list_namespace
# 更新表结构,增加一个 列族 为 csalter 'test', 'cs'
# 创建一个名为 test1 的表,这个表只有一个 列族 为 cf1,设定预分区,5个分区create 'test1', 'cf1', SPLITS => ['1000', '2000', '3000', '4000']
# 创建一个名为 test2 的表,这个表只有一个 列族 为 cf1,设定预分区,15个分区create 'test2', 'cf1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
# 查看所有表list# 列出某个namespace下的所有tablelist_namespace_tables 'default'
# 更多disable / is_disabled 禁用表/验证表是否被禁用enable / is_enabled 启用表/验证表是否已启用desc 查看表的详细信息alter 修改表结构exists 验证表是否存在drop / truncate 删除表/清空表(删除重建)
# 禁用表,检查是否禁用,删除表。删除之前必须禁用disable 'your_table_name'is_disabled 'your_table_name'drop 'your_table_name'
# 执行脚本,导出hbase shell <<EOF > hbase_tables.txtlist_namespacelist_namespaceEOFstatus
xxxxxxxxxxhbase shell# 查看当前版本version# 查看当前用户whoami# 查看 HBase 集群的摘要信息,包括集群状态、RegionServer 数量、Region 数量以及其他相关指标的汇总情况status 'summary'# 每个 RegionServer 上的 Region 分布情况status 'simple'# 每个 RegionServer 上的 Region 分布情况,包括每个表的 Region 数量、Region 所在的 RegionServer 等信息。# 3 个 RegionServer 的集群中,某个表名在每个 RegionServer 依次出现了 4 次/5 次/3 次,那么Region 数量为:4 + 5 + 3 = 12status 'detailed'# 查看目前负载均衡功能是否打开balancer_enabled# 打开负载均衡功能并确认balance_switch truebalancer_enabled
snapshot
xxxxxxxxxx# 创建快照snapshot 'sourceTable', 'snapshotName'# 恢复指定快照,先需要禁用原来的表,再恢复数据,最后重新启用表disable 'sourceTable'restore_snapshot 'snapshotName'enable 'sourceTable'# 或根据快照恢复出一个新表clone_snapshot 'snapshotName', 'tableName'# 将快照拷贝到备集群上hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot member_snapshot \-copy-to hdfs://备集群HDFS服务主NameNode节点IP:端口号/hbase -mappers 3
- 备集群的数据目录必须为HBASE根目录(/hbase)
- mappers表示MR任务需要提交的map个数
xxxxxxxxxx# 在备集群上使用restore命令在备集群自动新建表,以及与archive里的HFile建立link。restore_snapshot 'member_snapshot'# 列出快照list_snapshots# 查看快照详情snapshot_info 'snapshot_name'# 删除快照delete_snapshot 'snapshot_name'
RowCounter
利用hbase.RowCounter包执行MR任务
xxxxxxxxxxhbase org.apache.hadoop.hbase.mapreduce.RowCounter 'table_name'解析:Map-Reduce FrameworkMap input records: 输入记录数为 72464304 条。Map output records: Map 输出记录数为 0 条,这可能表示在 Map 阶段没有生成任何输出。GC time elapsed: GC(垃圾回收)所花费的时间为 1576 毫秒。CPU time spent: CPU 执行时间为 161690 毫秒。Physical memory snapshot: 物理内存快照为 1297866752 字节。Total committed heap usage: 堆内存使用量为 712507392 字节等相关信息。HBaseCounters这部分是 HBase 的计数器信息,包括数据传输、扫描行数、远程调用等:ROWS_SCANNED: 扫描的行数为 72464304 行。BYTES_IN_RESULTS: 结果中的字节数为 13086756887 字节等相关信息。org.apache.hadoop.hbase.mapreduce.RowCounterRowCounterMapperCountersROWS: 总行数为 72464304 行。File Input Format CountersBytes Read: 读取的字节数为 0 字节。File Output Format CountersBytes Written: 写入的字节数为 0 字节。
Hive
xxxxxxxxxxhive/beeline 命令类似sqlHive查看所有表/分区更新时间1. 查看分区show partitions table_name;2.查看分区更新时间- 获取hdfs路径desc formatted table_name;3. 通过dfs -ls < hdfs path>命令查看数据文件最新更新时间hdfs dfs -ls hdfs://hdfs-master:9000/user/hive/warehouse/ods.db/test;hdfs dfs -ls oss://...查看表结构 在spark-sql里面执行无法看到LOCATION等信息show create table table_name;## 导入数据到hive# hive直接导入本地文件hive -e "load data local inpath '$local_file_path' overwrite into table $table partition (pday = '$do_date');"# beeline要先上传到hdfs,再导入hdfs dfs -put -f "$local_file_path" "$hdfs_file_path"beeline -e "load data inpath '$hdfs_file_path' overwrite into table $table partition (pday = '$do_date');"## 导出--outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display Note that csv, and tsv are deprecated - use csv2, tsv2 insteadbeeline -e "show databases;"beeline --outputformat=csv2 -e "show databases;"
Hadoop 部署
准备工作
1、安装java 8,配置环境变量JAVA_HOME
2、要创建hadoop用户
3、配置ssh免密登录,ssh localhost 成功,才能使用脚本启动
单机模式
默认情况下,Hadoop 配置为以非分布式模式运行,作为单个 Java 进程。这对于调试很有用。 以下示例复制解压缩的 conf 目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
xxxxxxxxxx$ mkdir input$ cp etc/hadoop/*.xml input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'$ cat output/*$ mkdir wcinput$ vi wcinput/wc.inputhadoop hdfshadoop yarnmapreducemapreduce$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount wcinput wcoutput
伪分布式模式
Hadoop 也可以在单节点上以伪分布式模式运行,其中每个 Hadoop 守护进程在单独的 Java 进程中运行。
修改配置
xxxxxxxxxxetc/hadoop/core-site.xml<configuration><!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/data/hadoop-3.3.4/data/tmp</value></property></configuration>etc/hadoop/hdfs-site.xml:<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
启动集群
以下说明是在本地运行 MapReduce 作业。如果要在 YARN 上执行作业,请参阅YARN on Single Node。
xxxxxxxxxx格式化文件系统:bin/hdfs namenode -format启动 NameNode 守护进程和 DataNode 守护进程:sbin/start-dfs.shhadoop 守护进程日志输出被写入$HADOOP_LOG_DIR目录(默认为$HADOOP_HOME/logs)。# 或者分别启动 NameNode 守护进程和 DataNode 守护进程:sbin/hadoop-daemon.sh start namenodesbin/hadoop-daemon.sh start datanodesbin/hadoop-daemon.sh stop namenodesbin/hadoop-daemon.sh stop datanode浏览 NameNode 的 Web 界面;默认情况下,它位于:NameNode - http://localhost:9870/创建执行 MapReduce 作业所需的 HDFS 目录:bin/hdfs dfs -mkdir /userbin/hdfs dfs -mkdir /user/<username>bin/hdfs dfs -mkdir -p /user/root将输入文件复制到分布式文件系统中:bin/hdfs dfs -mkdir input # 相对路径,默认创建在 /user/<username>/ 下bin/hdfs dfs -put etc/hadoop/*.xml inputbin/hdfs dfs -mkdir wcinput # 相对路径,默认创建在 /user/<username>/ 下bin/hdfs dfs -put wcinput/wc.input wcinput运行提供的一些示例:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount wcinput wcoutput检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们:bin/hdfs dfs -get output outputcat output/*或者 查看分布式文件系统上的输出文件:bin/hdfs dfs -cat output/*完成后,使用以下命令停止守护进程:#sbin/stop-dfs.sh
YARN部署
使用 YARN 单节点
您可以通过设置一些参数并另外运行 ResourceManager 守护程序和 NodeManager 守护程序,以伪分布式模式在 YARN 上运行 MapReduce 作业。 以下指令假设上述指令的 1. ~ 4. 步骤已经执行。
修改配置
xxxxxxxxxxetc/hadoop/mapred-site.xml:<configuration><!-- 指定 ResourceManager 运行在 YARN 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property></configuration>etc/hadoop/yarn-site.xml:<configuration><!-- Reducer 获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value></property></configuration>
启动集群
xxxxxxxxxx启动 ResourceManager 守护进程和 NodeManager 守护进程:sbin/start-yarn.shsbin/yarn-daemon.sh start resourcemanagersbin/yarn-daemon.sh start nodemanagersbin/yarn-daemon.sh stop resourcemanagersbin/yarn-daemon.sh stop nodemanager浏览 ResourceManager 的 Web 界面;默认情况下,它位于:ResourceManager - http://localhost:8088/运行 MapReduce 作业。完成后,使用以下命令停止守护进程:#sbin/stop-yarn.sh
启用 YARN jobHistory
修改配置
xxxxxxxxxxetc/hadoop/mapred-site.xml:<configuration><!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>0.0.0.0:10020</value></property><!-- 历史服务器 WEB 端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>0.0.0.0:19888</value></property></configuration>
启动 JobHistoryServer
xxxxxxxxxxsbin/mr-jobhistory-daemon.sh start historyserversbin/mr-jobhistory-daemon.sh stop historyserver浏览 jobHistory 的 Web 界面;默认情况下,它位于:jobHistory - http://localhost:19888/
启用 YARN 日志聚集功能
修改配置
xxxxxxxxxxetc/hadoop/yarn-site.xml:<configuration><!-- 启用日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志保留时间: 7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
重启
xxxxxxxxxxsbin/yarn-daemon.sh stop resourcemanagersbin/yarn-daemon.sh stop nodemanagersbin/mr-jobhistory-daemon.sh stop historyserversbin/yarn-daemon.sh start resourcemanagersbin/yarn-daemon.sh start nodemanagersbin/mr-jobhistory-daemon.sh start historyserver
HBase部署
单机模式
默认 hbase.rootdir 是指向 /tmp/hbase-${user.name} ,也就说你会在重启后丢失数据(重启的时候操作系统会清理/tmp目录)
伪分布式模式
修改配置
xxxxxxxxxxconf/hbase-site.xml<!-- 将数据写到哪个目录 --><property><name>hbase.rootdir</name><value>hdfs://localhost:9000/hbase</value></property><!-- HLog 和 HFile 存储的复制计数。 不应大于 HDFS 数据节点计数。 --><property><name>dfs.replication</name><value>1</value><description>The replication count for HLog & HFile storage. Should not be greater than HDFS datanode count.</description></property><!-- HBase的运行模式。false是单机模式(默认),true是分布式模式。若为false,HBase和Zookeeper会运行在同一个JVM里面。 --><property><name>hbase.cluster.distributed</name><value>false</value><description>The mode the cluster will be in. Possible values arefalse: standalone and pseudo-distributed setups with managed Zookeepertrue: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)</description></property>
启动 Hbaes
xxxxxxxxxxbin/start-hbase.shbin/stop-hbase.sh
现在你运行的是单机模式的Hbaes。所有的服务都运行在一个JVM上,包括HBase和Zookeeper。
浏览 HBase 的 Web 界面;默认情况下,它位于: HBase - http://localhost:16010/
Hbase 无法启动
hbase regionserver 状态信息存储在 zookeeper中,元数据异常可能导致无法启动
xxxxxxxxxx# 清除 zookeeper 里相关hbase信息.zkCli.shls /deleteall .hbase# 清理Hbase MasterDatahdfs dfs -rm -r /hbase/MasterData
启动 Hbaes Shell
👉 常用命令
Hive部署
修改配置
xxxxxxxxxx# 配置环境变量export HADOOP_HOME=/data/hadoop-3.3.4export HIVE_HOME=/data/apache-hive-3.1.3-bin# 使用以下 HDFS 命令来创建/tmp和/user/hive/warehouse(又名hive.metastore.warehouse.dir)并设置它们chmod g+w ,然后才能在 Hive 中创建表$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse# 从 Hive 2.1 开始,我们需要运行下面的 schematool 命令作为初始化步骤。例如,我们可以使用“derby”作为 db 类型。$HIVE_HOME/bin/schematool -dbType derby -initSchema# 启动 Hive CLI (现在已弃用)$HIVE_HOME/bin/hive$HIVE_HOME/bin/hive -e "select * from test;"$HIVE_HOME/bin/hive -f /data/xxx/xxx.sql# 从 shell 运行 HiveServer2 和 Beeline: #$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT#会有权限问题,用下面的方法#Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):#User: hadoop is not allowed to impersonate hadoop (state=08S01,code=0)vi conf/hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 默认情况下,HiveServer2以提交查询的用户执行查询访问(true),如果设置为false,查询将以运行hiveserver2进程的用户访问。 --><property><name>hive.server2.enable.doAs</name><value>false</value><description>Setting this property to true will have HiveServer2 executeHive operations as the user making the calls to it.</description></property></configuration>
启动 Hive
xxxxxxxxxx$HIVE_HOME/bin/hiveserver2$HIVE_HOME/bin/beeline -u jdbc:hive2://localhost:10000# 为了测试目的,在同一进程中启动 Beeline 和 HiveServer2,以获得与 HiveCLI 类似的用户体验:$HIVE_HOME/bin/beeline -u jdbc:hive2://show databases;show tables;# 新建库 - 实际上仅更新了hive的元数据 metastore库的DBS表create database tttt;use tttt;# 强制删除有数据的数据库drop database tttt cascade;# 新建表 - 实际上仅更新了hive的元数据 metastore库的TBLS表create table test(id string);alter table test add columns(name string);# 插入数据 - 实际上数据写入到HDFS。也可以通过HDFS直接写入文件到对应目录insert into test values('1001');select * from test;# hive 中也可以执行hdfs命令dfs -ls /;# 默认数据报存在 HDFS 的 /user/hive/warehouse/<table>/
Kudu部署
Kudu 项目仅发布源代码版本,要在集群上部署 Kudu,请从源代码构建 Kudu
Kudu 无法启动
Kudu对时间同步要求比较严格,默认允许最大时间误差为2000000微秒(2秒),若还是无法启动,需要重启服务器
xxxxxxxxxx# 查看配置的时钟服务器连接情况 ,^*表示正常chronyc sources -v# 手动同步chronyc -a makestep# 修改 /etc/chrony.conf 并重启systemctl restart chronyd
Unable to init master catalog manager 这个错误是因为,kudu master 启动时发现元数据目录下空空如也,没有文件,所以拒绝启动。这种情况可能是上次启动时因为时间没同步,导致启动失败。所以影响本次的启动。或者该目录下有脏数据老的kudu目录数据。
xxxxxxxxxxE0221 12:45:49.662940 9726 master.cc:198] Unable to init master catalog manager: Not found: Unable to initialize catalog manager: Failed to initialize sys tables async: Unable to load consensus metadata for tablet 00000000000000000000000000000000: Unable to load consensus metadata for tablet 00000000000000000000000000000000: /mnt/disk1/kudu/master/meta/consensus-meta/00000000000000000000000000000000: No such file or directory (error 2)F0221 12:45:49.663147 9665 master_main.cc:107] Check failed: _s.ok() Bad status: Not found: Unable to initialize catalog manager: Failed to initialize sys tables async: Unable to load consensus metadata for tablet 00000000000000000000000000000000: Unable to load consensus metadata for tablet 00000000000000000000000000000000: /mnt/disk1/kudu/master/meta/consensus-meta/00000000000000000000000000000000: No such file or directory (error 2)
解决方法:将报错对应的wal目录和data目录清空能恢复。若还是无法启动,需要重启服务器
xxxxxxxxxx# 备份kudu数据目录 /mnt/disk1/kuducp -a kudu kudu_bakrm -rf kudumkdir kudu
创建表
xxxxxxxxxxCREATE TABLE IF NOT EXISTS kudu_table(id bigint comment '主键',name string comment '名字',sex string comment '性别',PRIMARY KEY(id))PARTITION BY HASH PARTITIONS 16STORED AS KUDUTBLPROPERTIES ('kudu.master_addresses' = '10.181.77.46,10.181.77.47,10.181.77.48');## 在 Impala 中使用Kudu# 如果未启用 HMS 集成,通过 Kudu API 或其他集成(如 Apache Spark)创建的表在 Impala 中不会自动可见。# 要查询它们,您必须首先在 Impala 中创建一个外部表,以将 Kudu 表映射到 Impala 数据库CREATE EXTERNAL TABLE my_mapping_tableSTORED AS KUDUTBLPROPERTIES ('kudu.table_name' = 'my_kudu_table');# 创建Kudu表不支持以下Impala关键字PARTITIONLOCATIONROW FORMAT# Impala 使用 SQL 将数据插入到kudu表插入单行INSERT INTO my_first_table VALUES (99, "sarah");使用单个语句插入三行INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");通过查询包含原始数据的表将值插入到 Kudu 表中,如下例所示:INSERT INTO my_kudu_table SELECT * FROM legacy_data_import_table;INSERT和主键唯一性违规在大多数关系数据库中,如果您尝试插入已经插入的行,则插入会失败,因为主键会重复。请参阅、和操作期间的故障INSERTUPDATEDELETE。然而,Impala 不会使查询失败。相反,它将生成警告,但继续执行插入语句的其余部分。如果插入的行旨在替换现有行,UPSERT则可以使用INSERT.INSERT INTO my_first_table VALUES (99, "sarah");UPSERT INTO my_first_table VALUES (99, "zoe");-- the current value of the row is 'zoe'更改表属性您可以通过更改表的属性来更改与给定 Kudu 表相关的 Impala 元数据。这些属性包括表名、Kudu 主地址列表以及该表是由 Impala(内部)还是外部管理。重命名 Impala 映射表ALTER TABLE my_table RENAME TO my_new_table;在 Impala 3.2 及更低版本中,使用 ALTER TABLE my_table RENAME 语句重命名表只会重命名 Impala 映射表,无论该表是内部表还是外部表。从 Impala 3.3 开始,重命名表也会重命名底层 Kudu 表。为内部表重命名底层 Kudu 表在 Impala 2.11 及更低版本中,可以通过更改kudu.table_name属性来重命名底层 Kudu 表:ALTER TABLE my_internal_tableSET TBLPROPERTIES('kudu.table_name' = 'new_name')将外部表重新映射到不同的 Kudu 表如果另一个应用程序在 Impala 下重命名了 Kudu 表,则可以重新映射外部表以指向不同的 Kudu 表名称。ALTER TABLE my_external_table_SET TBLPROPERTIES('kudu.table_name' = 'some_other_kudu_table')更改 Kudu 主地址ALTER TABLE my_tableSET TBLPROPERTIES('kudu.master_addresses' = 'kudu-new-master.example.com:7051');将内部管理的表更改为外部ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');使用 Impala 删除 Kudu 表如果表是在 Impala 中作为内部表创建的,CREATE TABLE则使用 标准DROP TABLE语法会删除底层 Kudu 表及其所有数据。如果表是作为外部表创建的,使用CREATE EXTERNAL TABLE,Impala 和 Kudu 之间的映射将被删除,但 Kudu 表及其所有数据保持不变。DROP TABLE my_first_table;
浏览 Kudu 的 Web 界面;默认情况下,它位于: Kudu - http://localhost:8050/
Impala部署
Impala 项目发布的是源码包
浏览 Impala 的 Web 界面;默认情况下,它位于: Impala - http://localhost:25000/ w3m http://localhost:25000/
Livy部署
要运行Livy服务器,需要安装Apache Spark。Livy至少需要Spark 1.6,并支持Scala 2.10和2.11 spark的构建。
修改配置
xxxxxxxxxx# 配置环境变量export SPARK_HOME=/usr/lib/sparkexport HADOOP_CONF_DIR=/etc/hadoop/conf
Livy使用的配置文件是:
- livy.conf:包含服务器配置。Livy 发行版附带默认配置文件 列出可用配置键及其默认值的模板。
- spark-blacklist.conf:列出不允许用户覆盖的 Spark 配置选项。这些选项将 限制为其默认值或 Livy 使用的 Spark 配置中设置的值。
- log4j.properties:Livy 日志记录的配置。定义日志级别以及日志消息将写入的位置。 默认配置模板会将日志消息打印到 stderr。
启动 Livy
xxxxxxxxxx./bin/livy-server start
Livy端口:8998
Knox部署
安装
xxxxxxxxxx# 安装目录{GATEWAY_HOME}=/usr/local/knoxunzip knox-{VERSION}.zip
启动嵌入在 Knox 中的 LDAP
xxxxxxxxxxcd {GATEWAY_HOME}bin/ldap.sh start
创建主密钥
xxxxxxxxxxcd {GATEWAY_HOME}bin/knoxcli.sh create-master
CLI 将提示您输入主密钥(即密码)。
启动Knox
xxxxxxxxxxcd {GATEWAY_HOME}bin/gateway.sh start
以这种方式启动网关时,该过程将在后台运行。日志文件将写入{GATEWAY_HOME}/logs ,进程 ID 文件 (PID) 将写入{GATEWAY_HOME}/pids 。
要停止使用该脚本启动的网关,请使用以下命令:
xxxxxxxxxxcd {GATEWAY_HOME}bin/gateway.sh stop
如果由于某种原因,网关停止了,而不是使用上面的命令,您可能需要清除跟踪PID:
xxxxxxxxxxcd {GATEWAY_HOME}bin/gateway.sh clean
注意:此命令还将清除 {GATEWAY_HOME}/logs 目录中的任何 .out 和 .err 文件,因此请谨慎使用。
使用 Knox 访问 Hadoop
通过网关调用WebHDFS上的LISTSTATUS操作。这将返回HDFS的根(即/)目录的目录列表。
xxxxxxxxxxcurl -i -k -u guest:guest-password -X GET \'https://localhost:8443/gateway/sandbox/webhdfs/v1/?op=LISTSTATUS'
上述命令的结果应类似于下面的输出。返回的确切信息取决于Hadoop集群中HDFS中的内容。成功执行此命令至少证明网关已正确配置为提供对 WebHDFS 的访问。这并不一定意味着任何其他服务都已正确配置为可访问。若要验证这一点,请参阅服务详细信息中各个服务的部分。
xxxxxxxxxxHTTP/1.1 200 OKContent-Type: application/jsonContent-Length: 760Server: Jetty(6.1.26){"FileStatuses":{"FileStatus":[{"accessTime":0,"blockSize":0,"group":"hdfs","length":0,"modificationTime":1350595859762,"owner":"hdfs","pathSuffix":"apps","permission":"755","replication":0,"type":"DIRECTORY"},{"accessTime":0,"blockSize":0,"group":"mapred","length":0,"modificationTime":1350595874024,"owner":"mapred","pathSuffix":"mapred","permission":"755","replication":0,"type":"DIRECTORY"},{"accessTime":0,"blockSize":0,"group":"hdfs","length":0,"modificationTime":1350596040075,"owner":"hdfs","pathSuffix":"tmp","permission":"777","replication":0,"type":"DIRECTORY"},{"accessTime":0,"blockSize":0,"group":"hdfs","length":0,"modificationTime":1350595857178,"owner":"hdfs","pathSuffix":"user","permission":"755","replication":0,"type":"DIRECTORY"}]}}
通过 Knox 将文件放入 HDFS 中。
xxxxxxxxxxcurl -i -k -u guest:guest-password -X PUT \'https://localhost:8443/gateway/sandbox/webhdfs/v1/tmp/LICENSE?op=CREATE'curl -i -k -u guest:guest-password -T LICENSE -X PUT \'{Value of Location header from response above}'
通过 Knox 获取 HDFS 中的文件。
xxxxxxxxxxcurl -i -k -u guest:guest-password -X GET \'https://localhost:8443/gateway/sandbox/webhdfs/v1/tmp/LICENSE?op=OPEN'curl -i -k -u guest:guest-password -X GET \'{Value of Location header from command response above}'